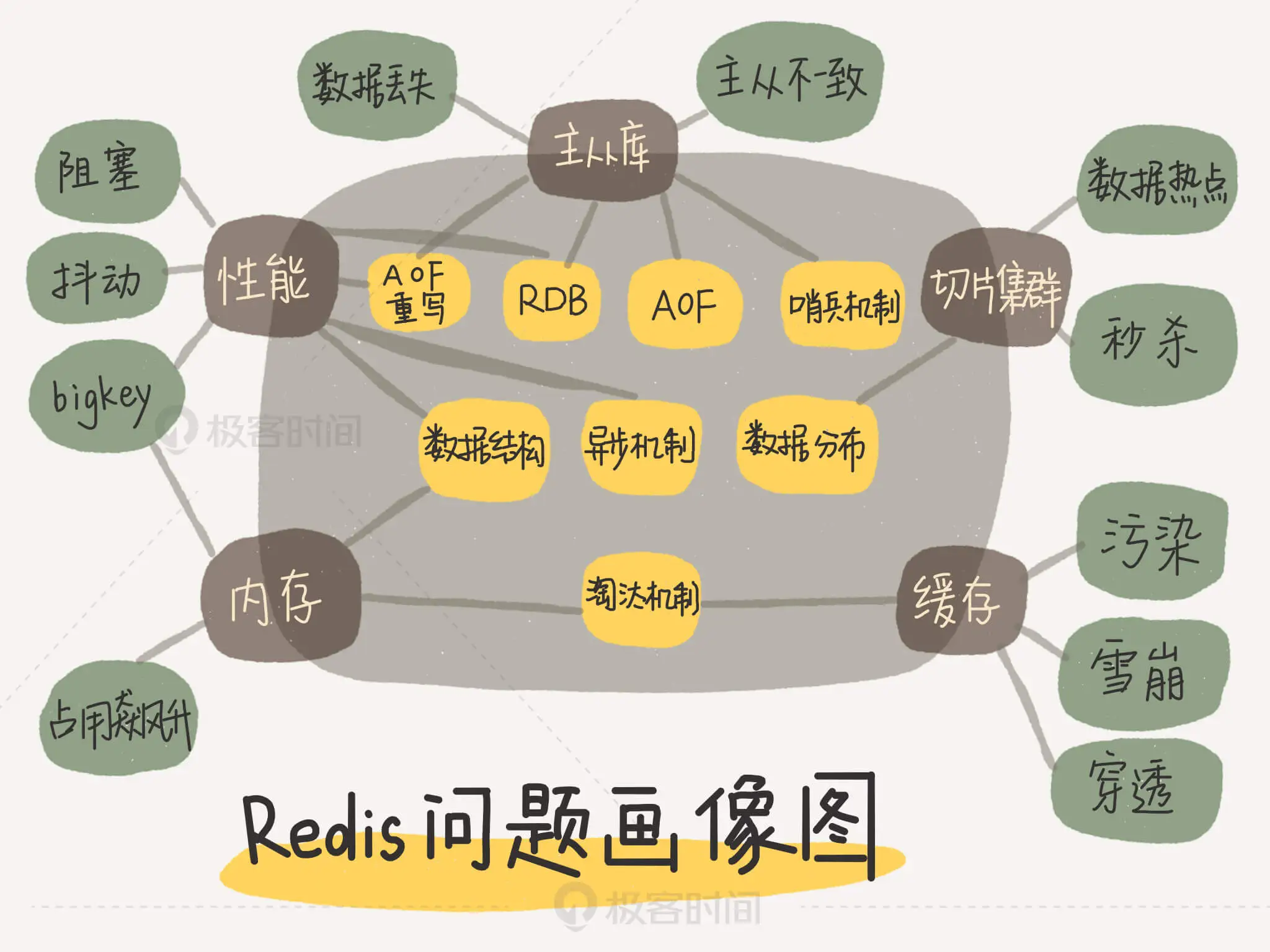
redis核心技术与实战
开篇

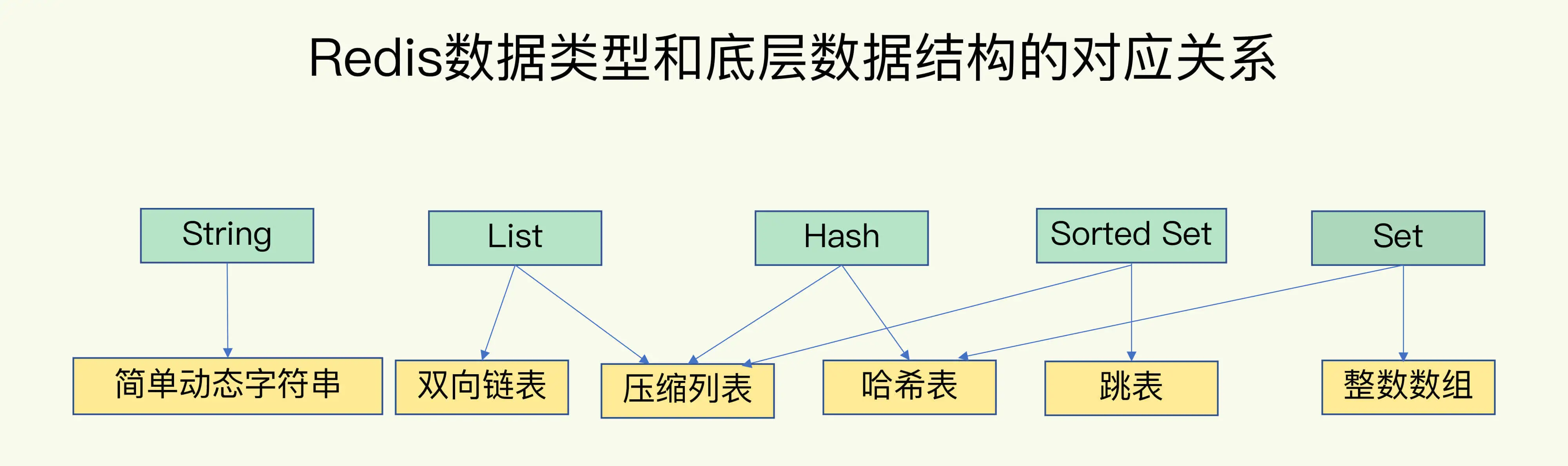
02 数据结构
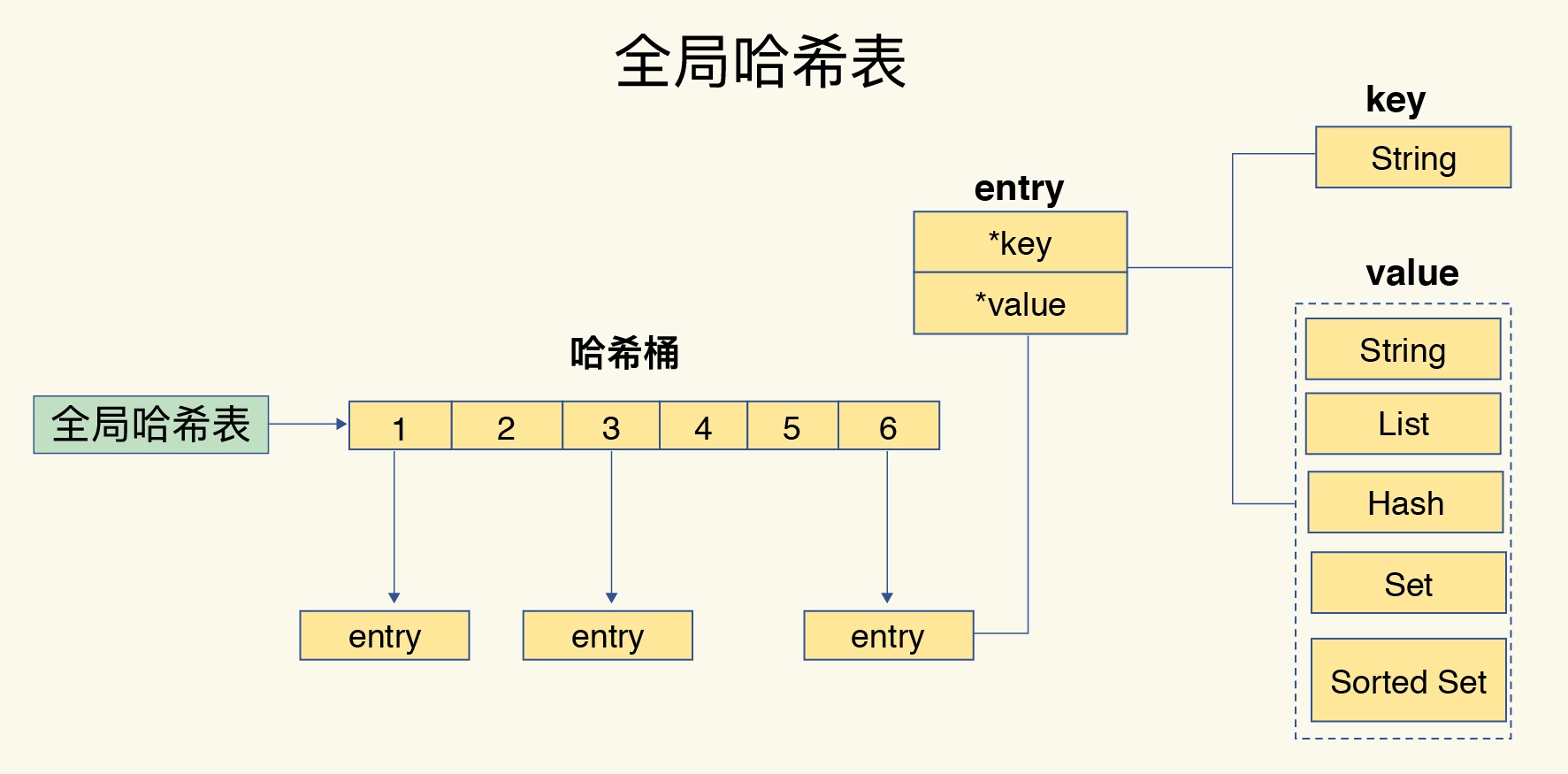
哈希桶中的 entry 元素中保存了key和value指针,分别指向了实际的键和值,这样一来,即使值是一个集合,也可以通过*value指针被查找到。
当你往 Redis 中写入大量数据后,就可能发现操作有时候会突然变慢了。这其实是因为你忽略了一个潜在的风险点,那就是哈希表的冲突问题和 rehash 可能带来的操作阻塞。
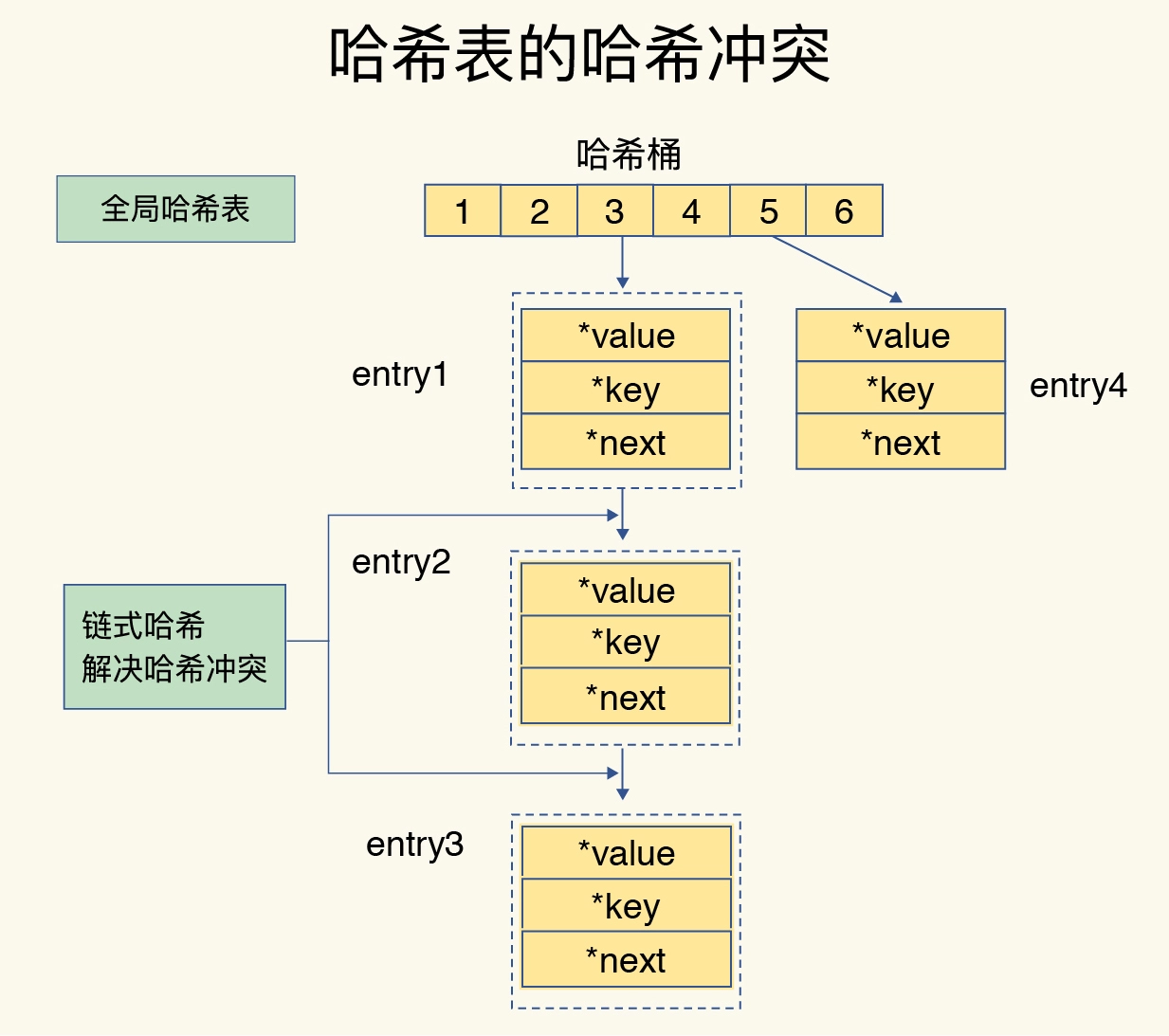
rehash
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 释放哈希表 1 的空间。
Redis 采用了渐进式 rehash。
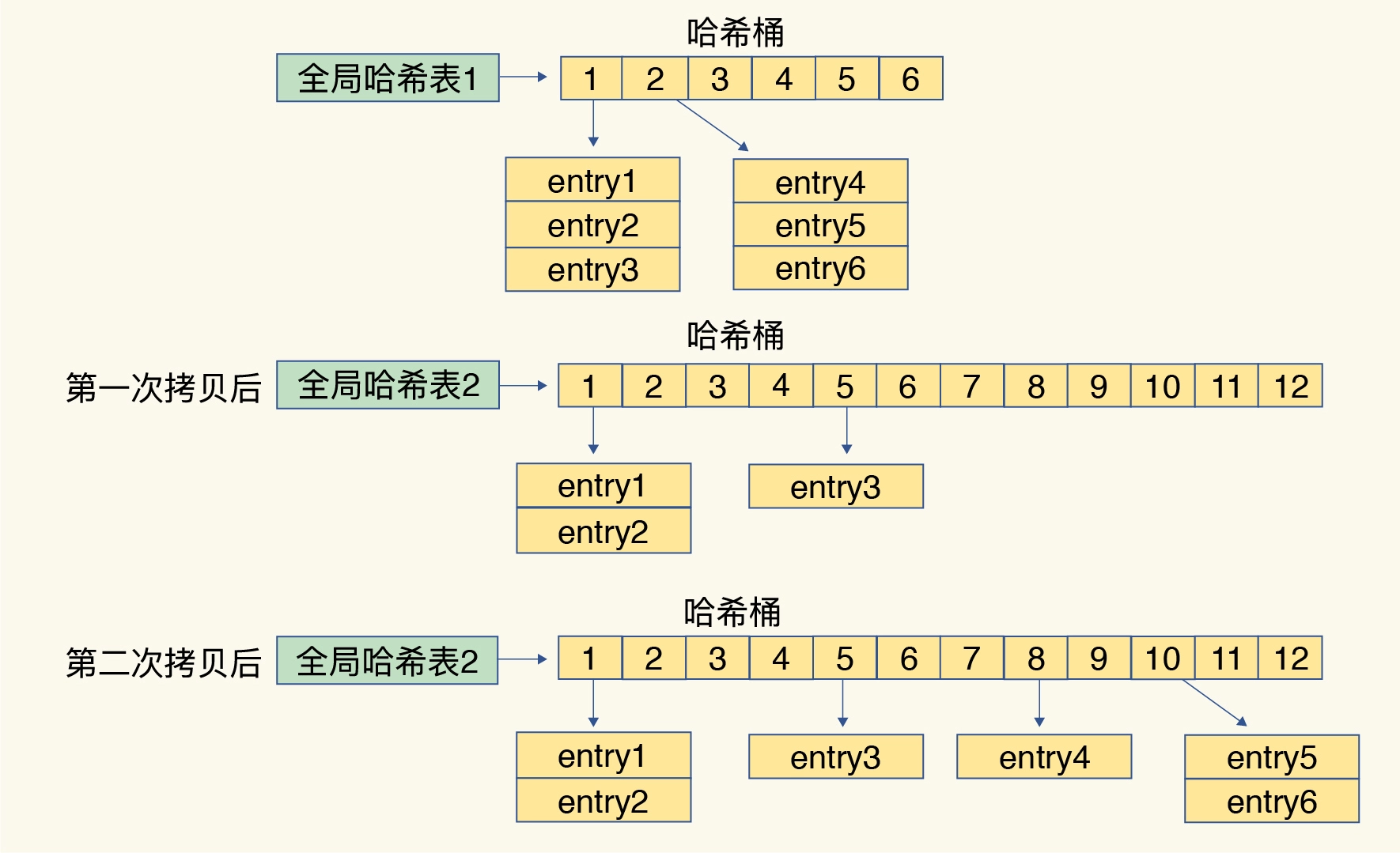
把一次性大量拷贝的开销,分摊到了多次处理请求的过程中
压缩表
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。

在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。
跳表
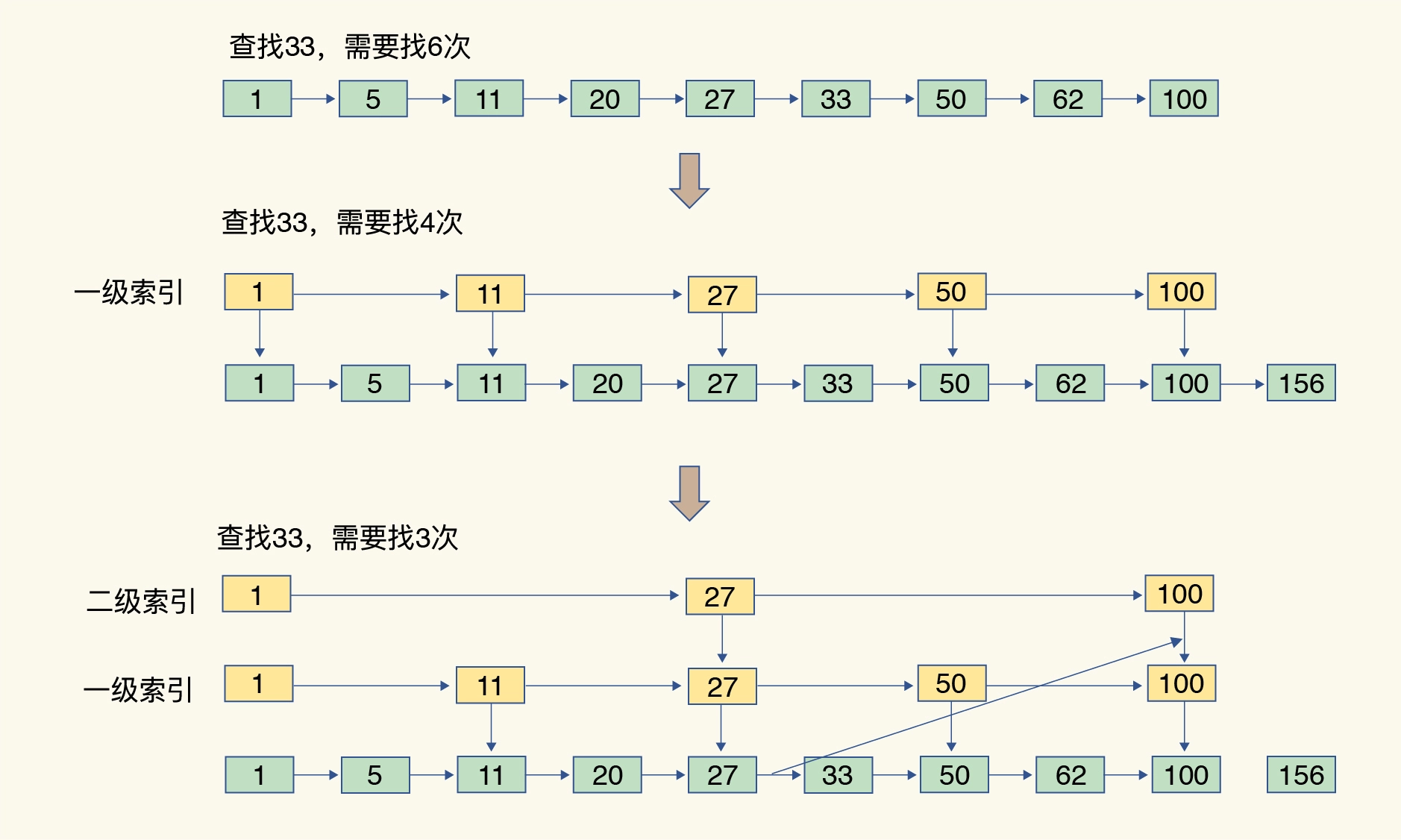
增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位
跳表的查找复杂度就是 O(logN)
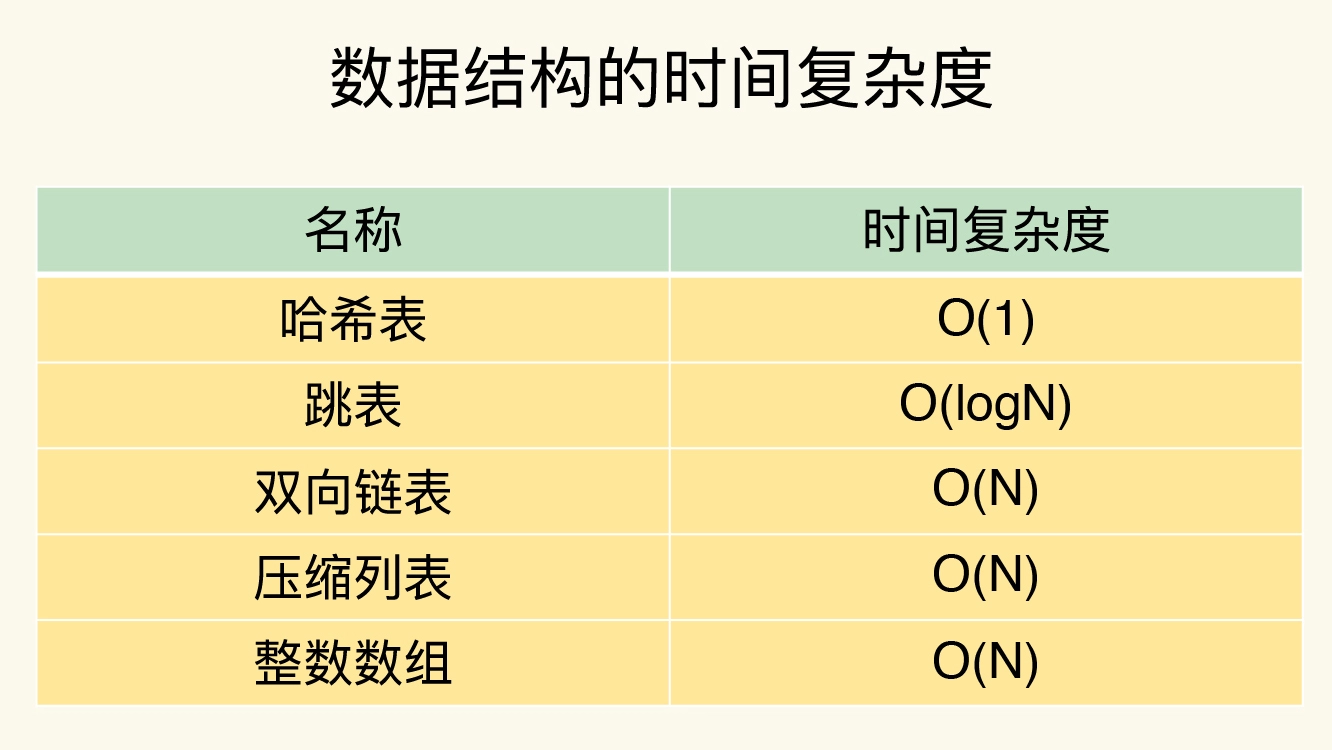
不同操作的复杂度
- 单元素操作是基础;
- 范围操作非常耗时;统计操作通常高效;
- 例外情况只有几个。
03 高性能IO模型:为什么单线程Redis能那么快?
Redis 为什么用单线程?
多线程的开销
上下文切换 争抢共享资源
单线程 Redis 为什么那么快?
内存上完成
高效的数据结构,例如哈希表和跳表
Redis 采用了多路复用机制
基本 IO 模型与阻塞点
基于多路复用的高性能 I/O 模型
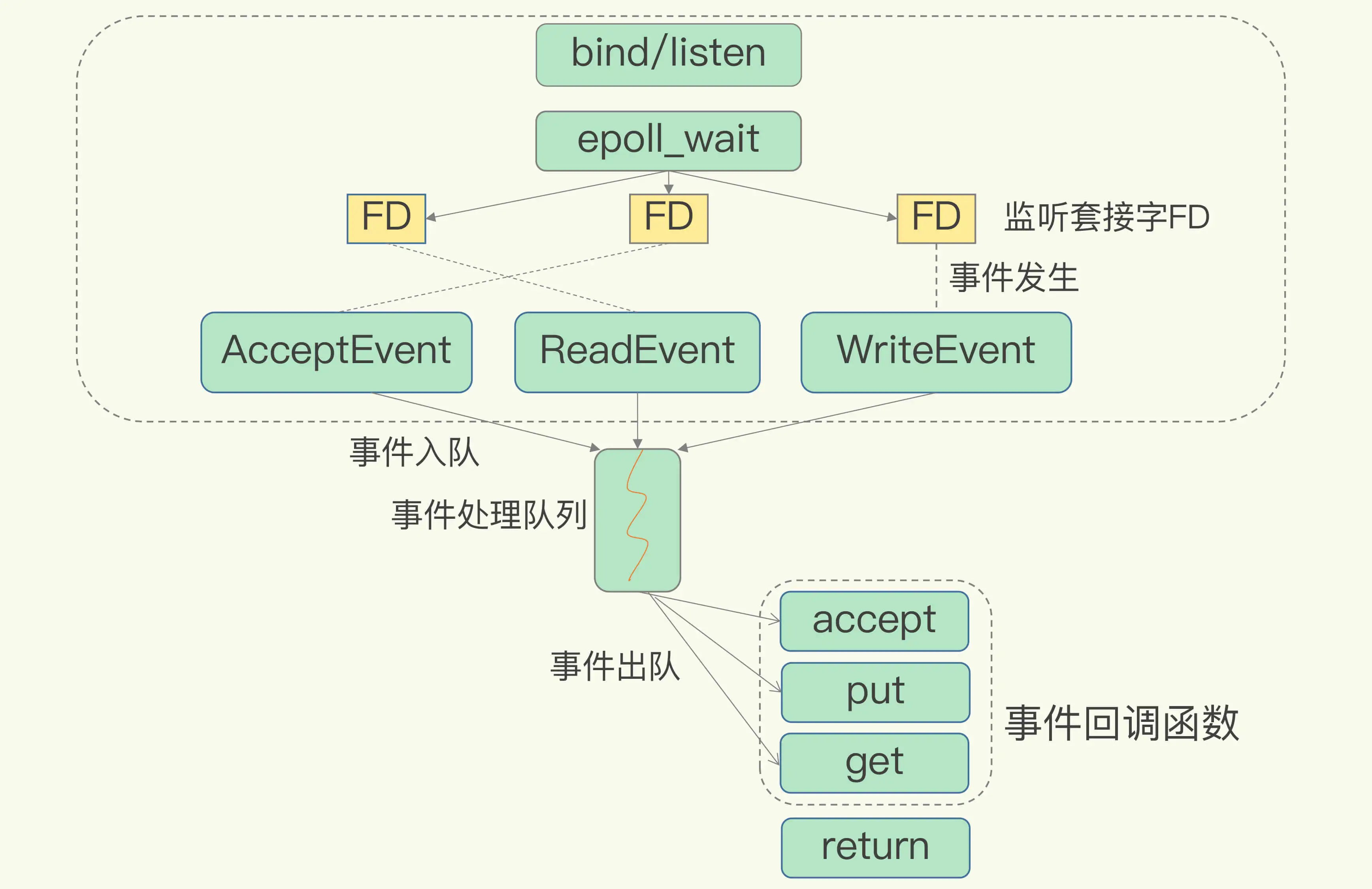
为了在请求到达时能通知到 Redis 线程,select/epoll 提供了基于事件的回调机制,即针对不同事件的发生,调用相应的处理函数。
select/epoll 一旦监测到 FD 上有请求到达时,就会触发相应的事件。
这些事件会被放进一个事件队列,Redis 单线程对该事件队列不断进行处理。这样一来,Redis 无需一直轮询是否有请求实际发生,这就可以避免造成 CPU 资源浪费。同时,Redis 在对事件队列中的事件进行处理时,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。
04 AOF日志:宕机了,Redis如何避免数据丢失?
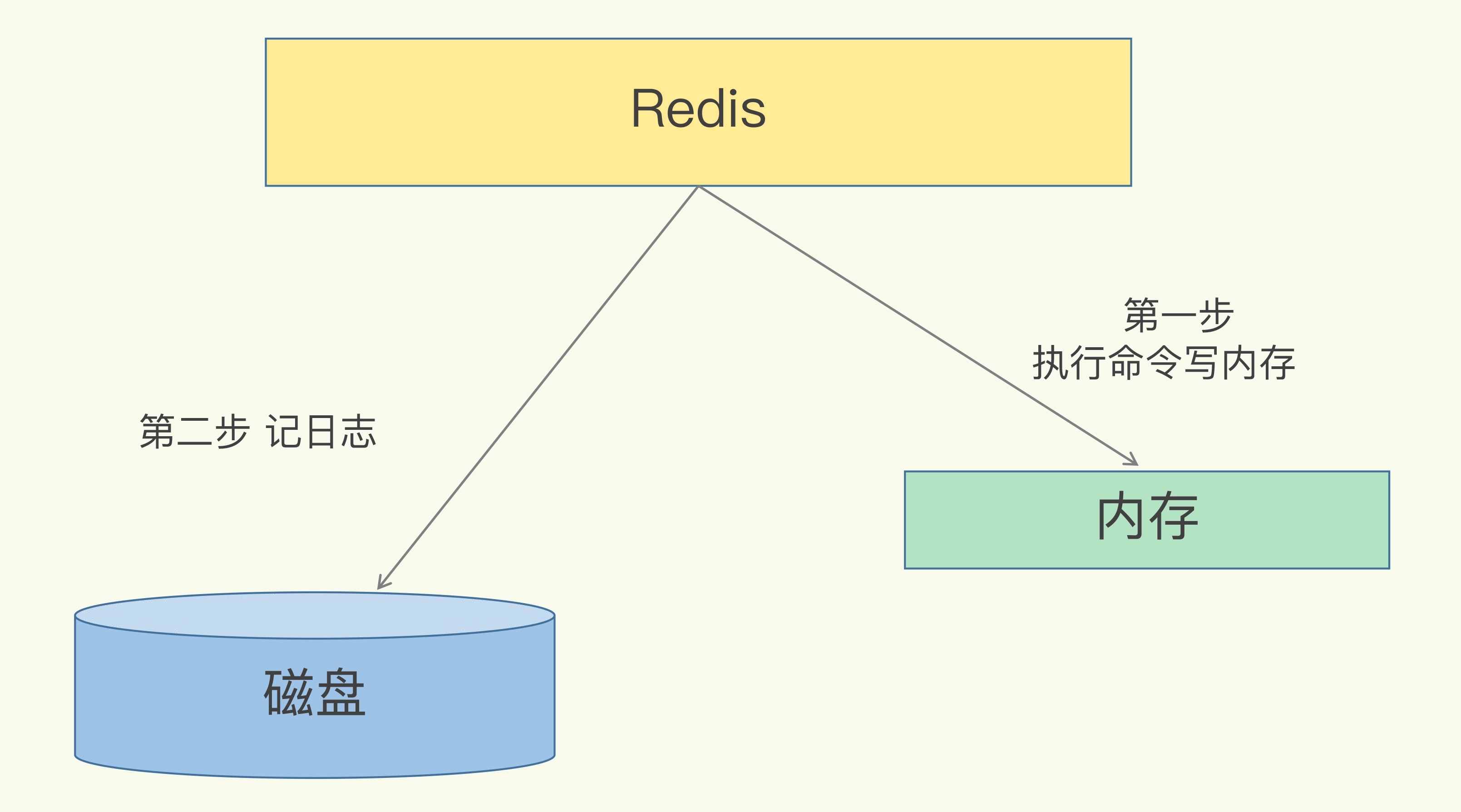

写后日志这种方式,就是先让系统执行命令,只有命令能执行成功,才会被记录到日志中
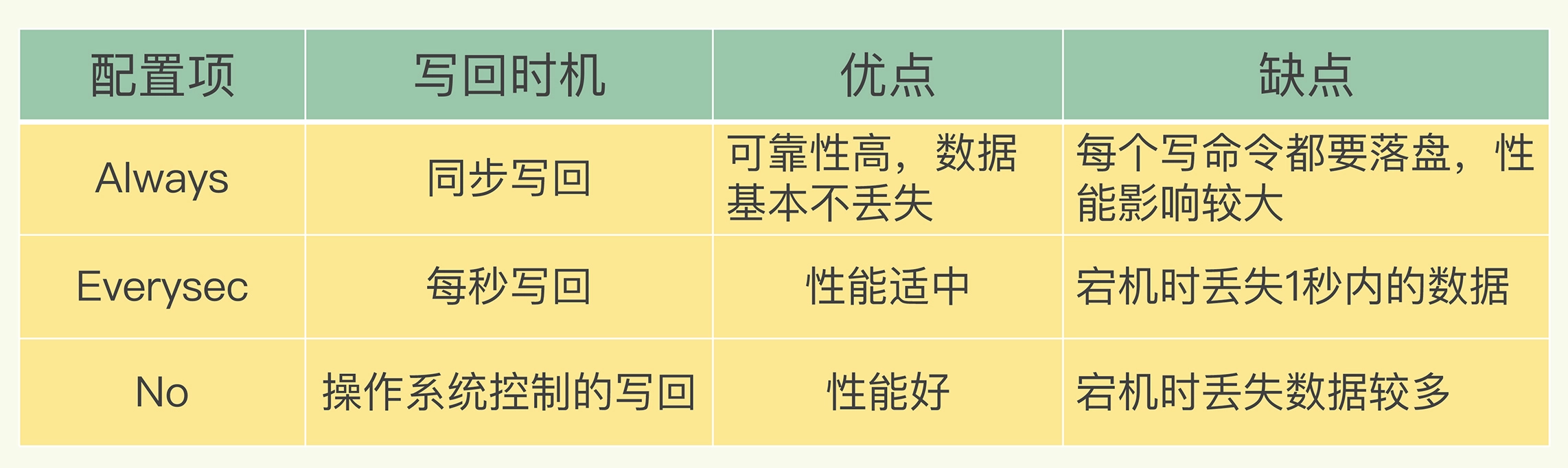
三种写回策略
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
AOF日志文件太大了怎么办?
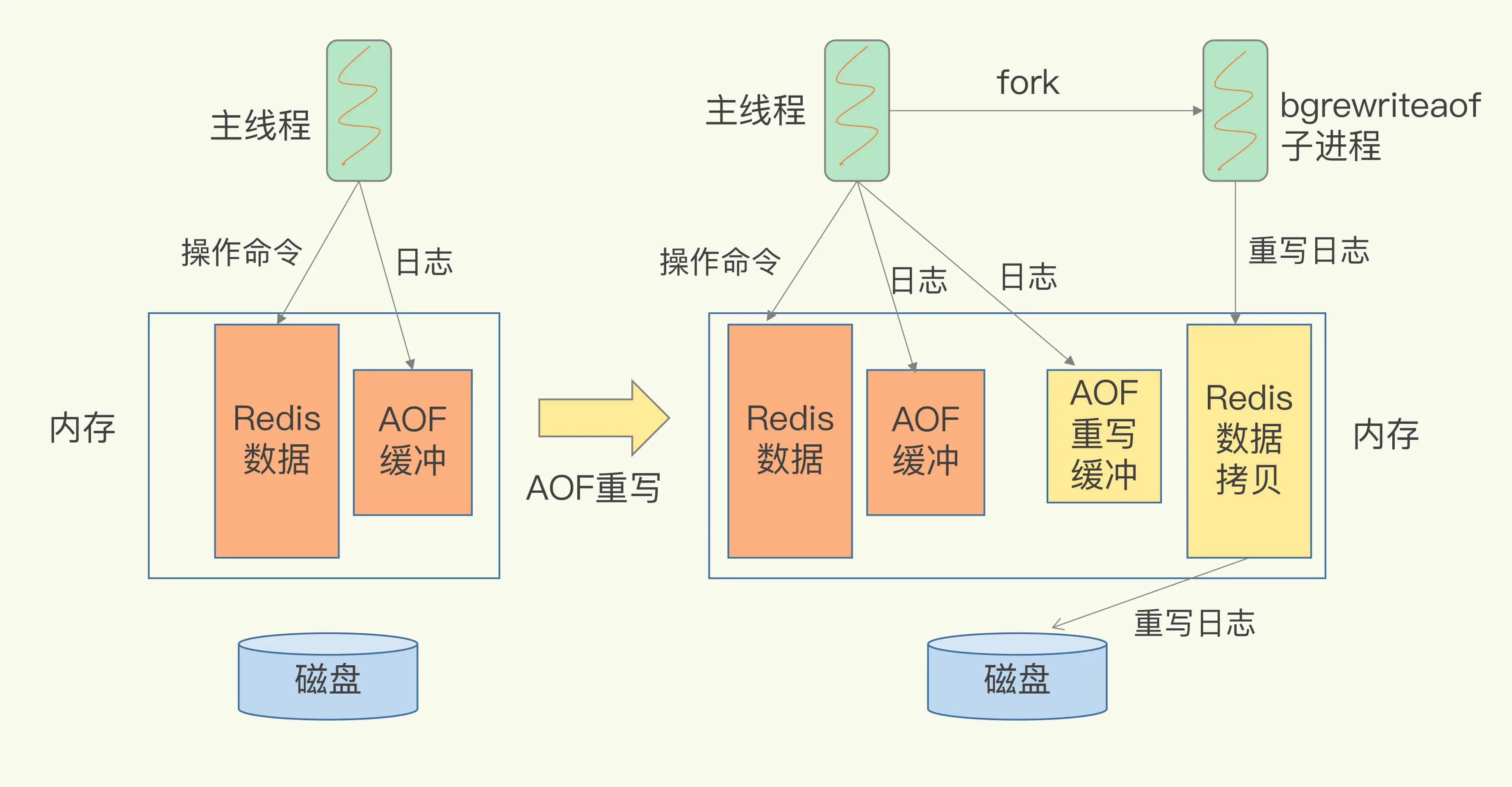
AOF 重写机制就是在重写时,Redis 根据数据库的现状创建一个新的 AOF 文件
旧日志文件中的多条命令,在重写后的新日志中变成了一条命令。
AOF 重写会阻塞吗?
和 AOF 日志由主线程写回不同,重写过程是由后台子进程 bgrewriteaof 来完成的,这也是为了避免阻塞主线程,导致数据库性能下降。
“一个拷贝,两处日志”。
05 内存快照:宕机后,Redis如何实现快速恢复?
RDB 全量快照
Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。
- save:在主线程中执行,会导致阻塞;
- bgsave:创建一个子进程,专门用于写入 RDB 文件,避免了主线程的阻塞,这也是 Redis RDB 文件生成的默认配置。
写时复制技术
主线程要修改一块数据(例如图中的键值对 C),那么,这块数据就会被复制一份,生成该数据的副本(键值对 C’)。然后,主线程在这个数据副本上进行修改。同时,bgsave 子进程可以继续把原来的数据(键值对 C)写入 RDB 文件。
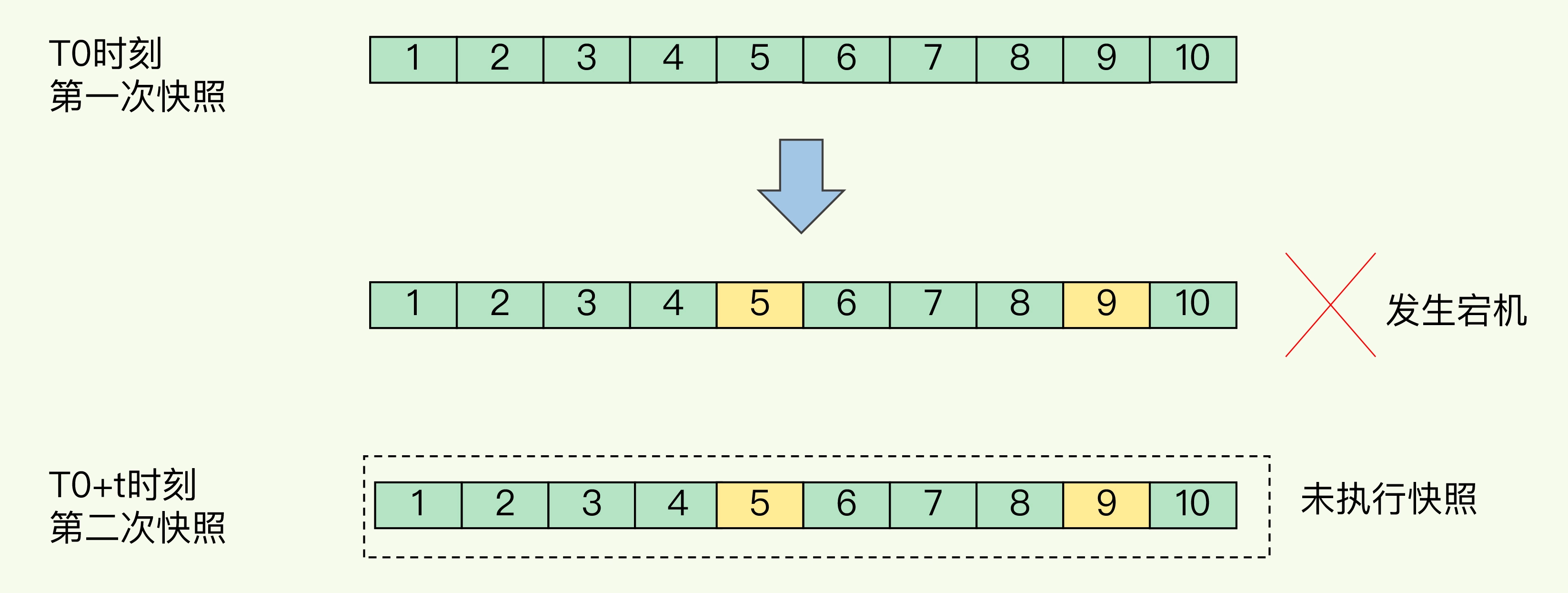
如果频繁地执行全量快照
频繁将全量数据写入磁盘,会给磁盘带来很大压力
子进程在创建后不会再阻塞主线程,但是,fork 这个创建过程本身会阻塞主线程
内存快照和AOF混合使用
06 数据同步:主从库如何实现数据一致?
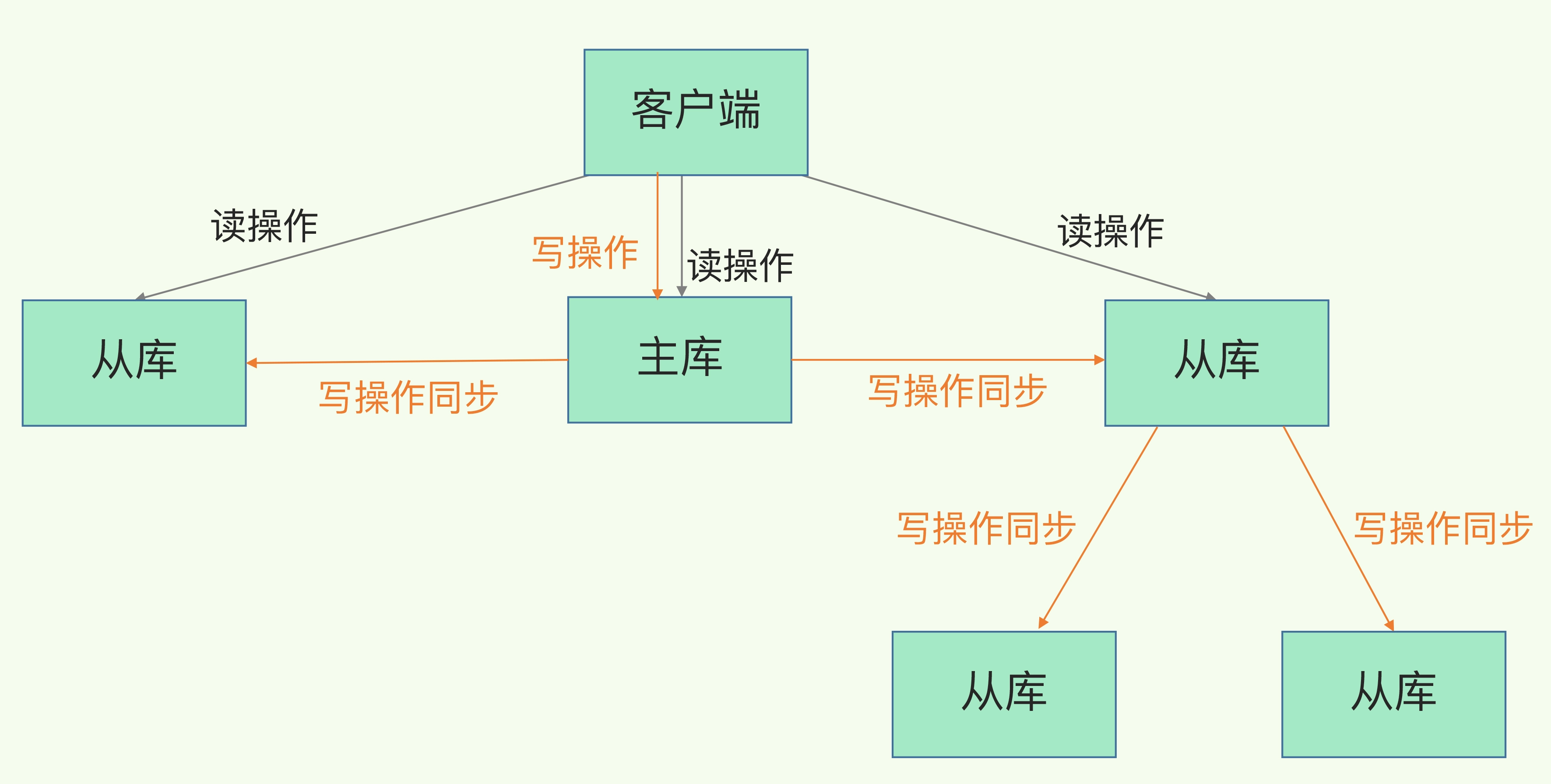
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。

Redis主从库和读写分离
主从库间如何进行第一次同步?

主从级联模式分担全量复制时的主库压力
主从库间网络断了怎么办?
07 哨兵机制:主库挂了,如何不间断服务?
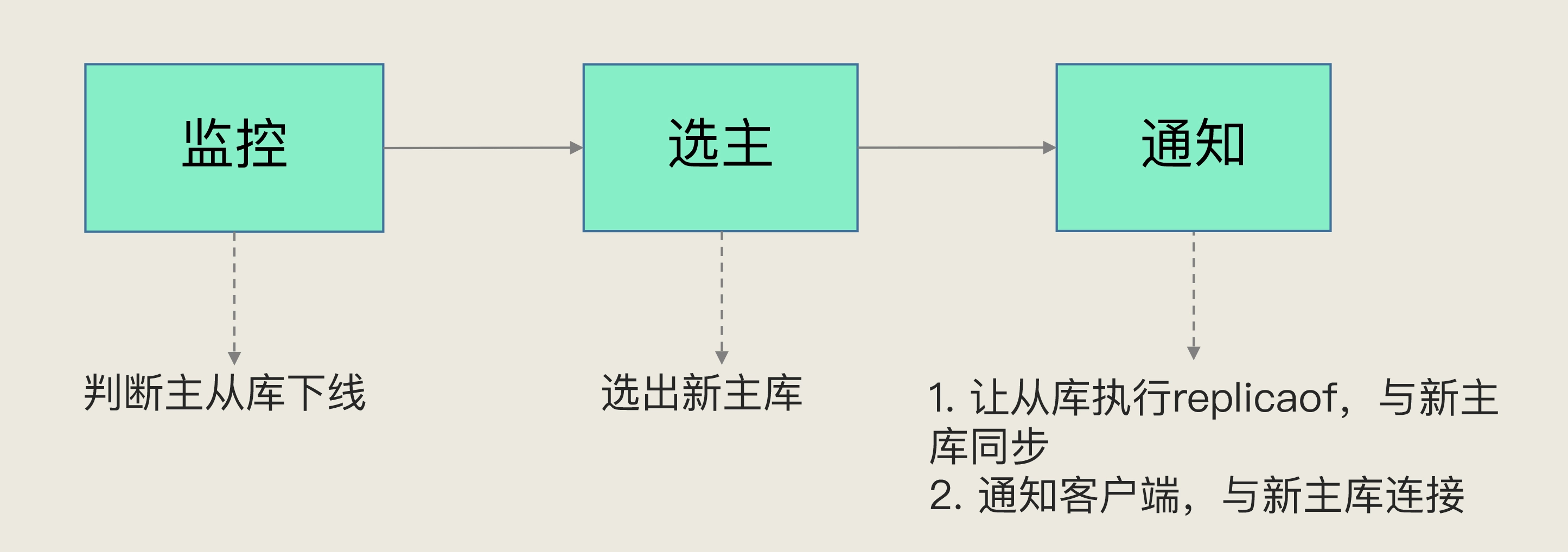
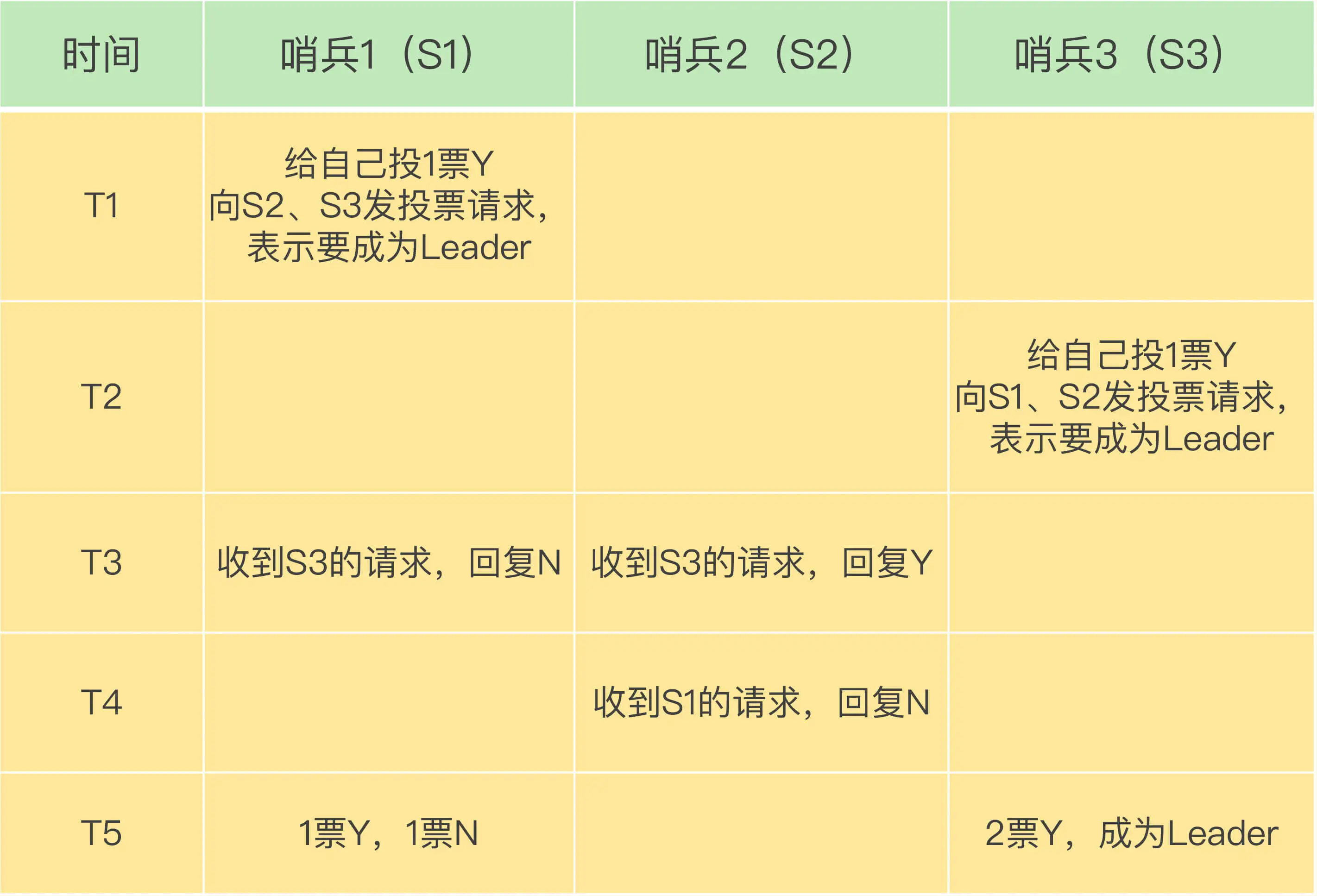
哨兵机制的基本流程
哨兵主要负责的就是三个任务:监控、选主(选择主库)和通知。
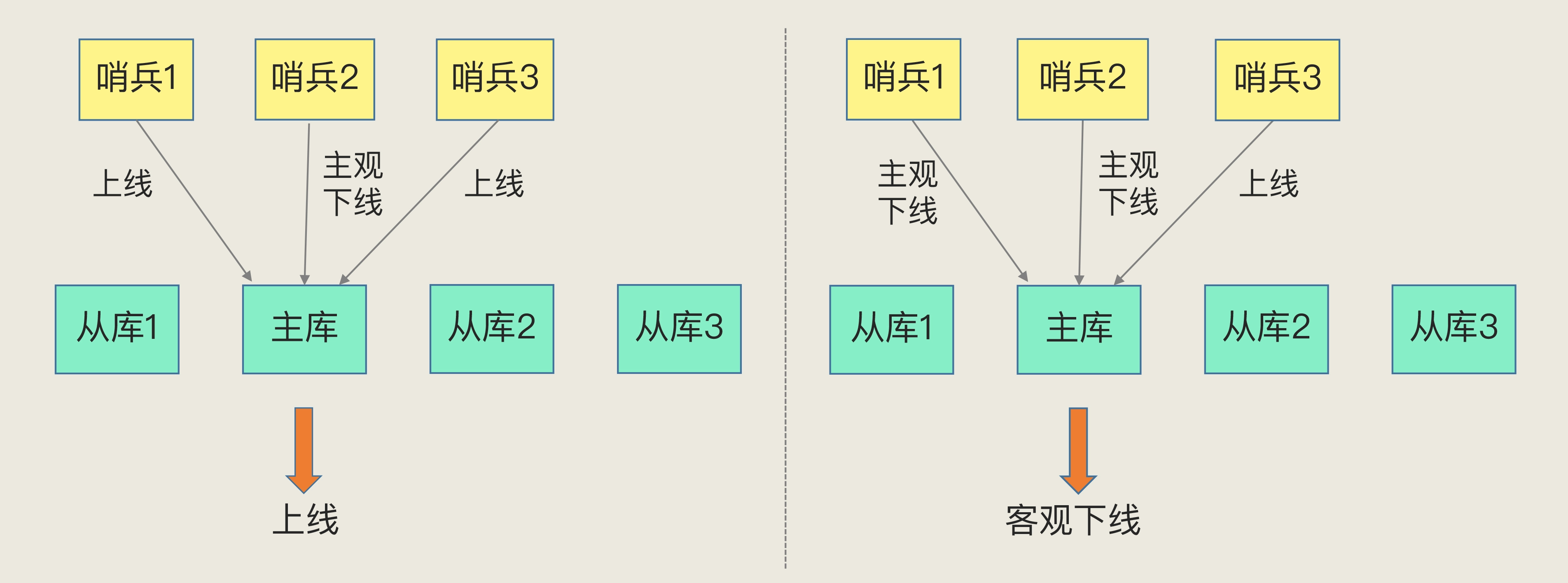
主观下线和客观下线
哨兵集群
如何选定新主库?
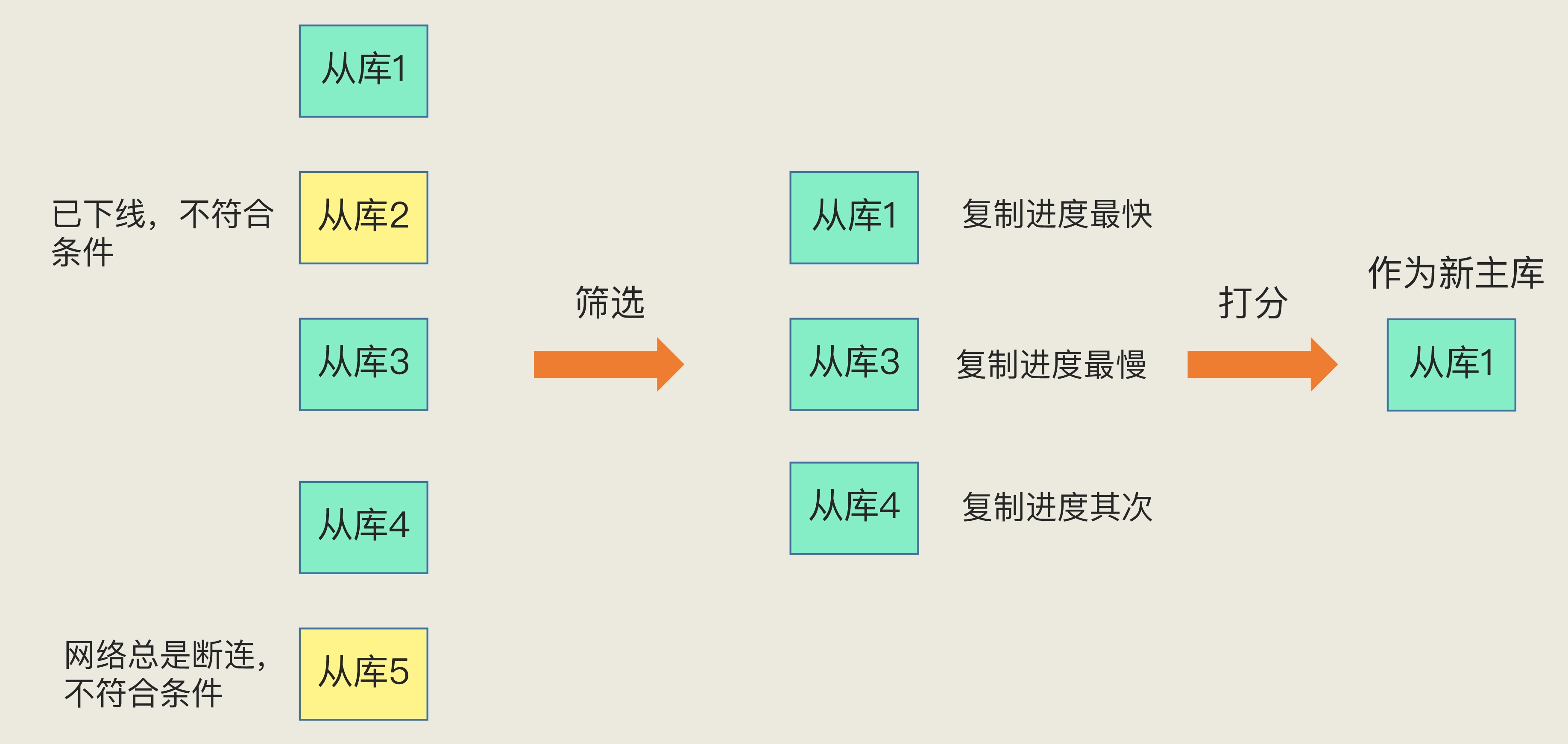
从库的当前在线状态,还要判断它之前的网络连接状态
第一轮 优先级最高的从库得分高
第二轮 和旧主库同步程度最接近的从库得分高
第三轮 ID 号小的从库得分高。
08 哨兵集群:哨兵挂了,主从库还能切换吗?
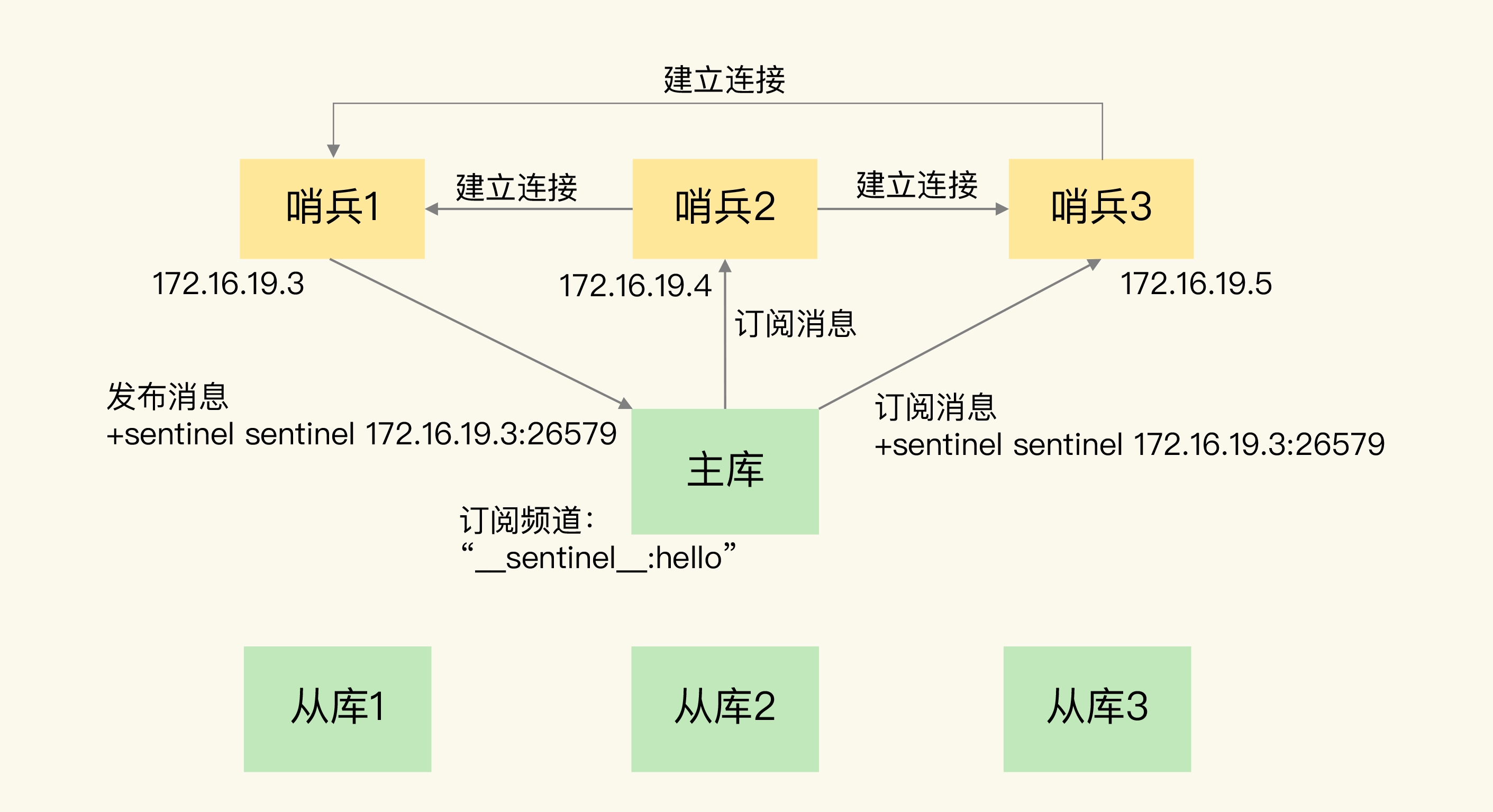
基于 pub/sub 机制的哨兵集群组成
主库上有一个名为“sentinel:hello”的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
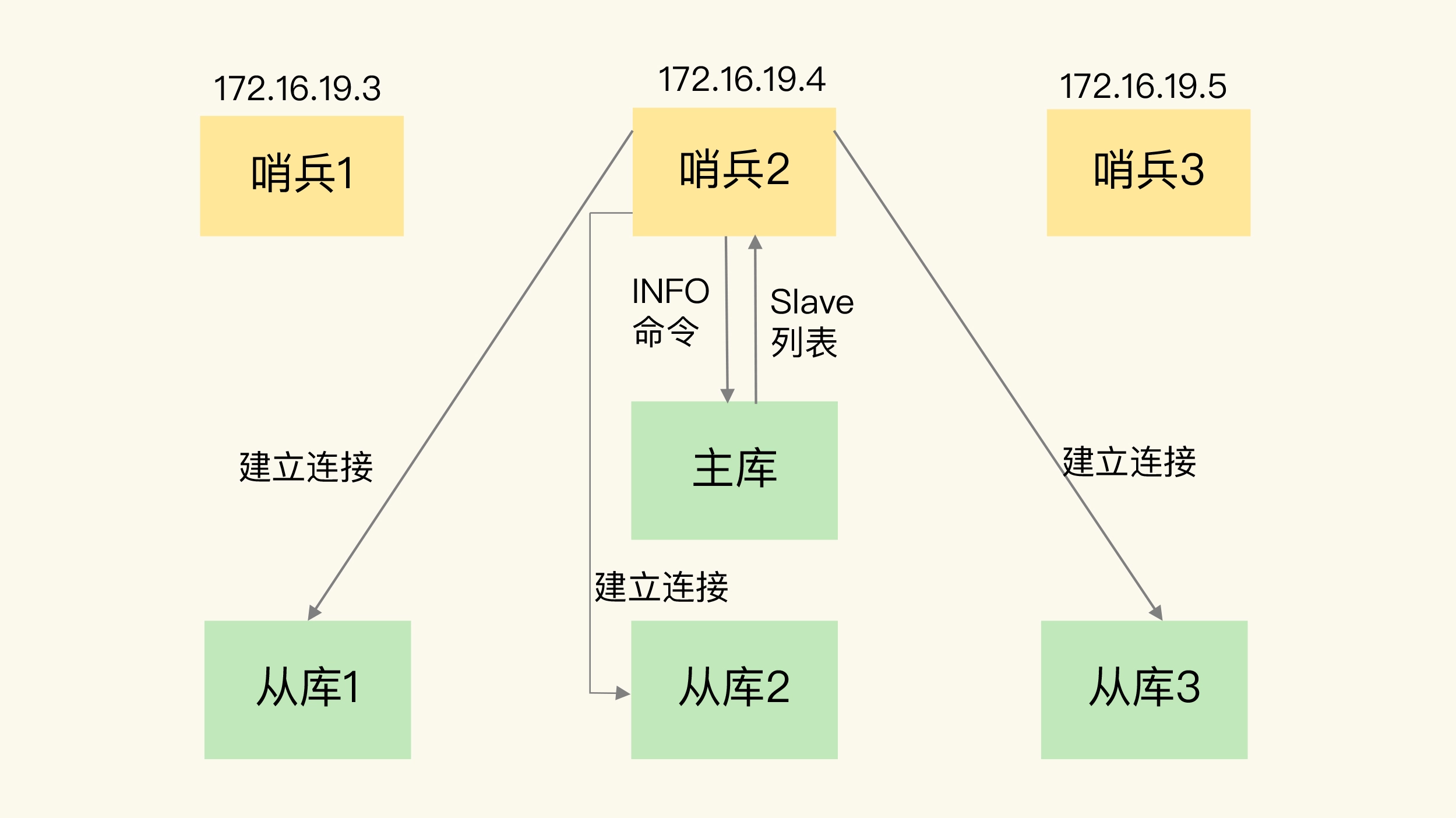
哨兵又通过 INFO 命令,获得了从库连接信息,也能和从库建立连接,并进行监控了。
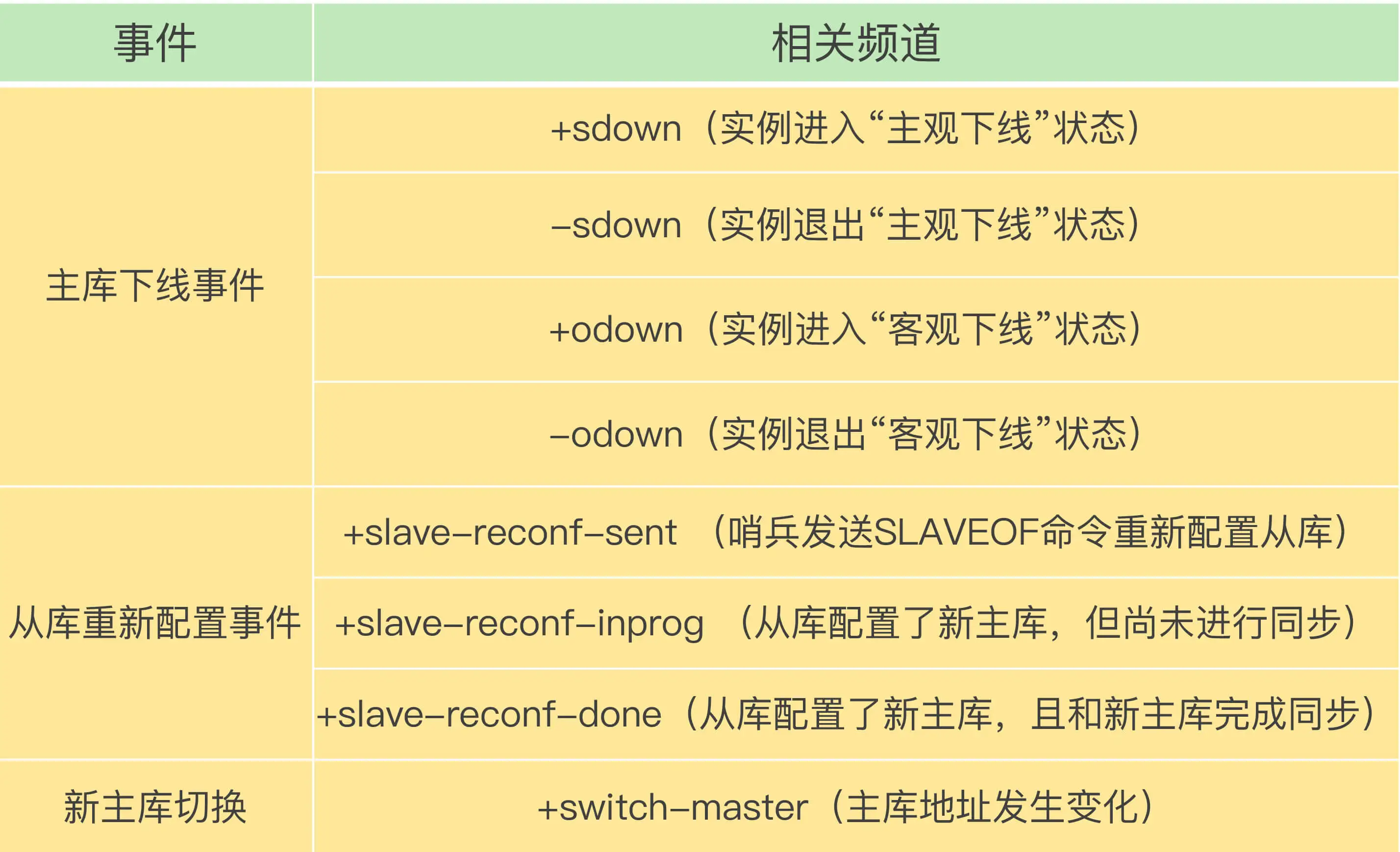
客户端读取哨兵的配置文件后,可以获得哨兵的地址和端口,和哨兵建立网络连接。然后,我们可以在客户端执行订阅命令,来获取不同的事件消息。
由哪个哨兵执行主从切换?
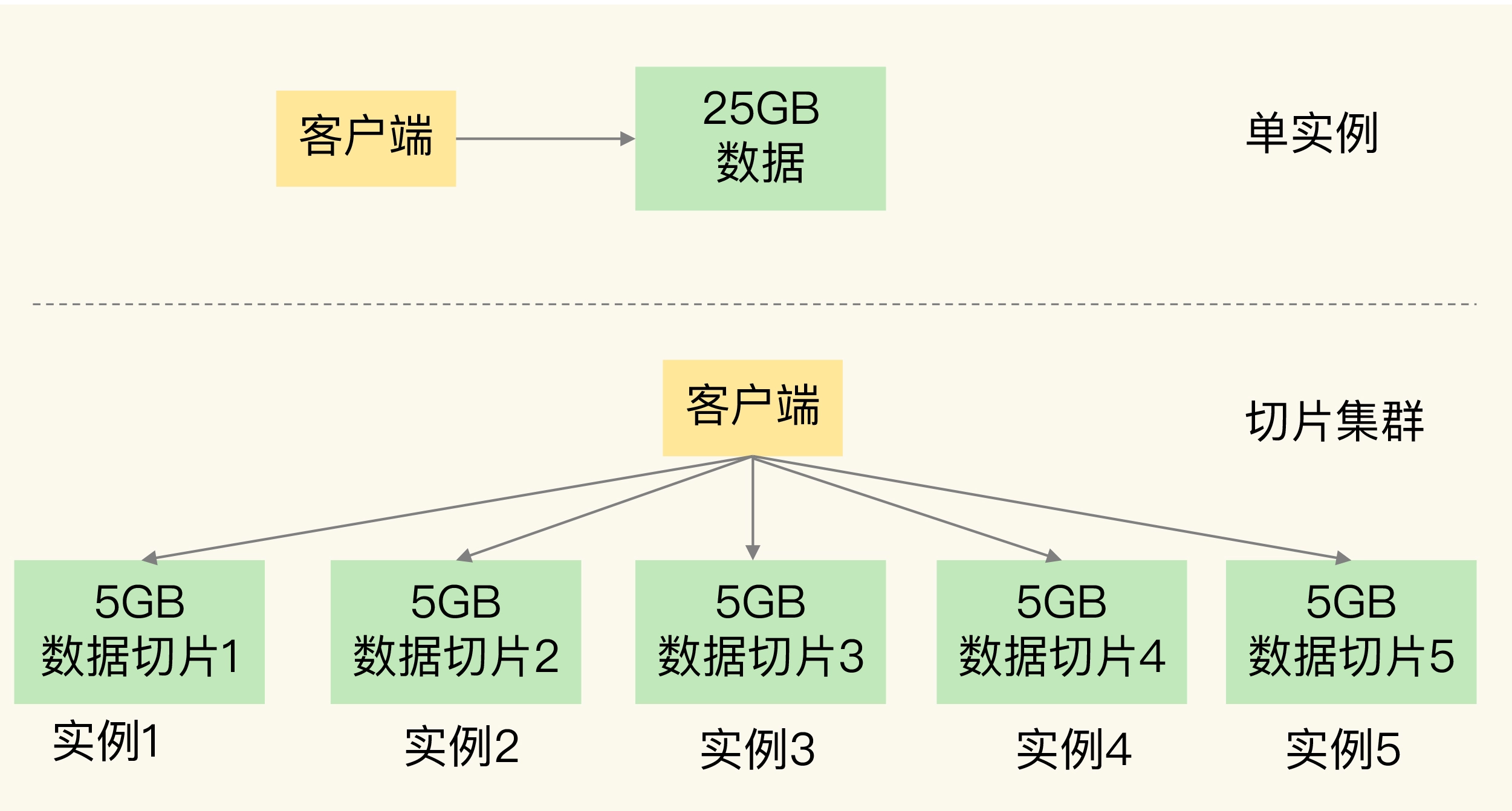
09 切片集群:数据增多了,是该加内存还是加实例?
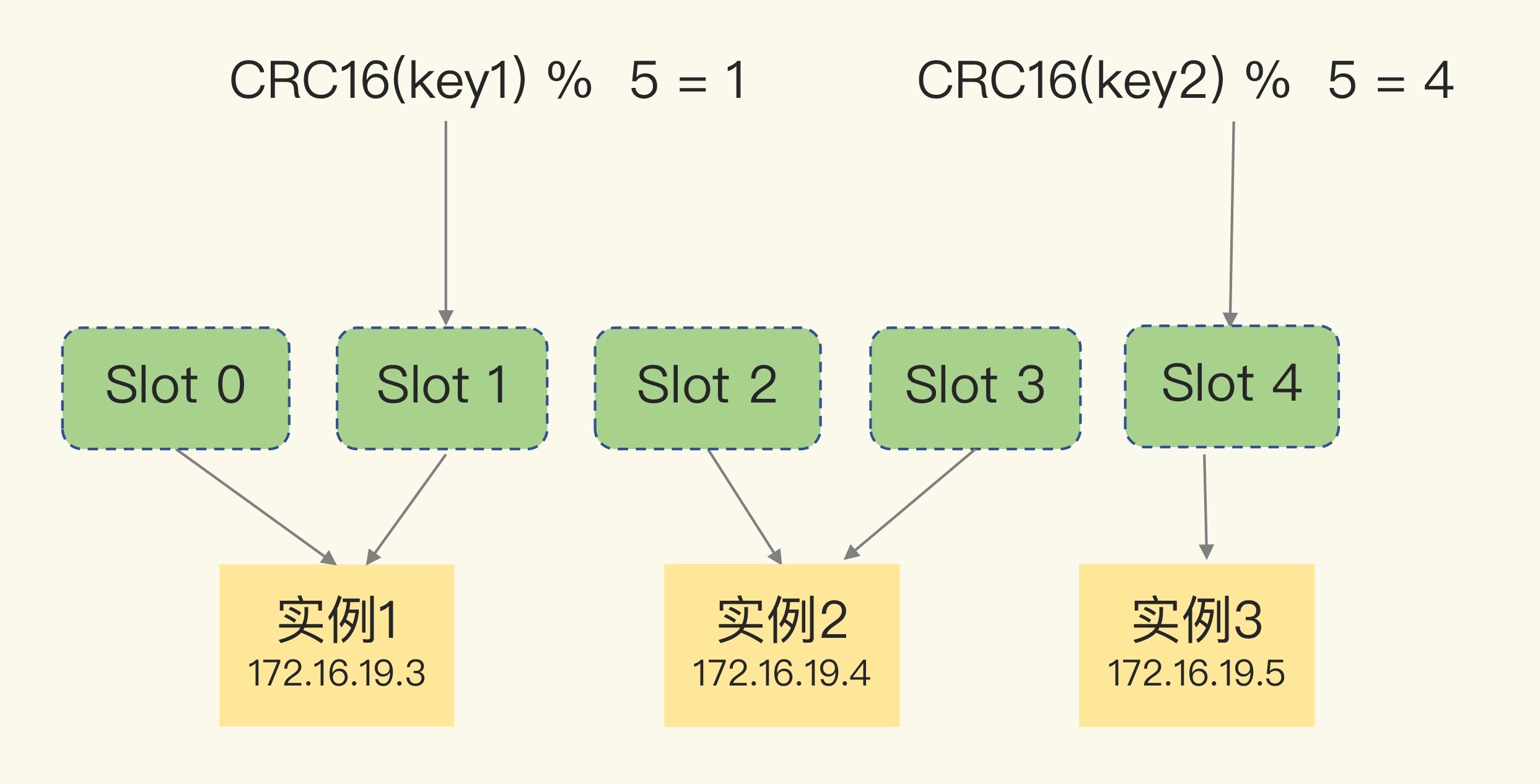
Redis Cluster 方案采用哈希槽(Hash Slot,接下来我会直接称之为 Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。
首先根据键值对的 key,按照CRC16 算法计算一个 16 bit 的值;然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽
每个实例上的槽个数为 16384/N 个
Redis 实例会把自己的哈希槽信息发给和它相连接的其它实例,来完成哈希槽分配信息的扩散
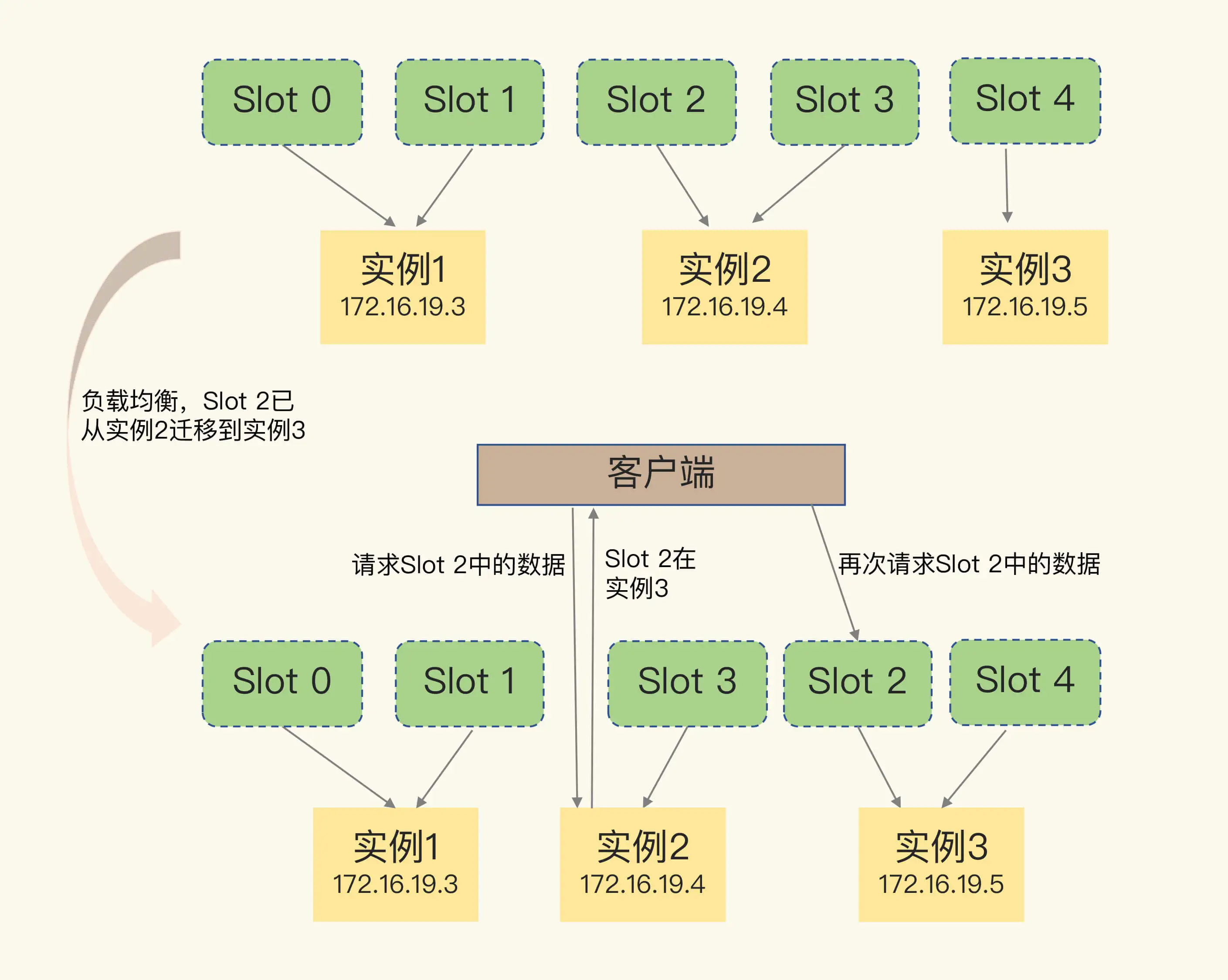
- 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
- 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
实例之间还可以通过相互传递消息,获得最新的哈希槽分配信息
Redis Cluster 方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令。
那客户端又是怎么知道重定向时的新实例的访问地址呢?当客户端把一个键值对的操作请求发给一个实例时,如果这个实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回下面的 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。
11 “万金油”的String,为什么不好用了?
为什么 String 类型内存开销大?

- buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个“\0”,这就会额外占用 1 个字节的开销。
- len:占 4 个字节,表示 buf 的已用长度。
- alloc:也占个 4 字节,表示 buf 的实际分配长度,一般大于 len。
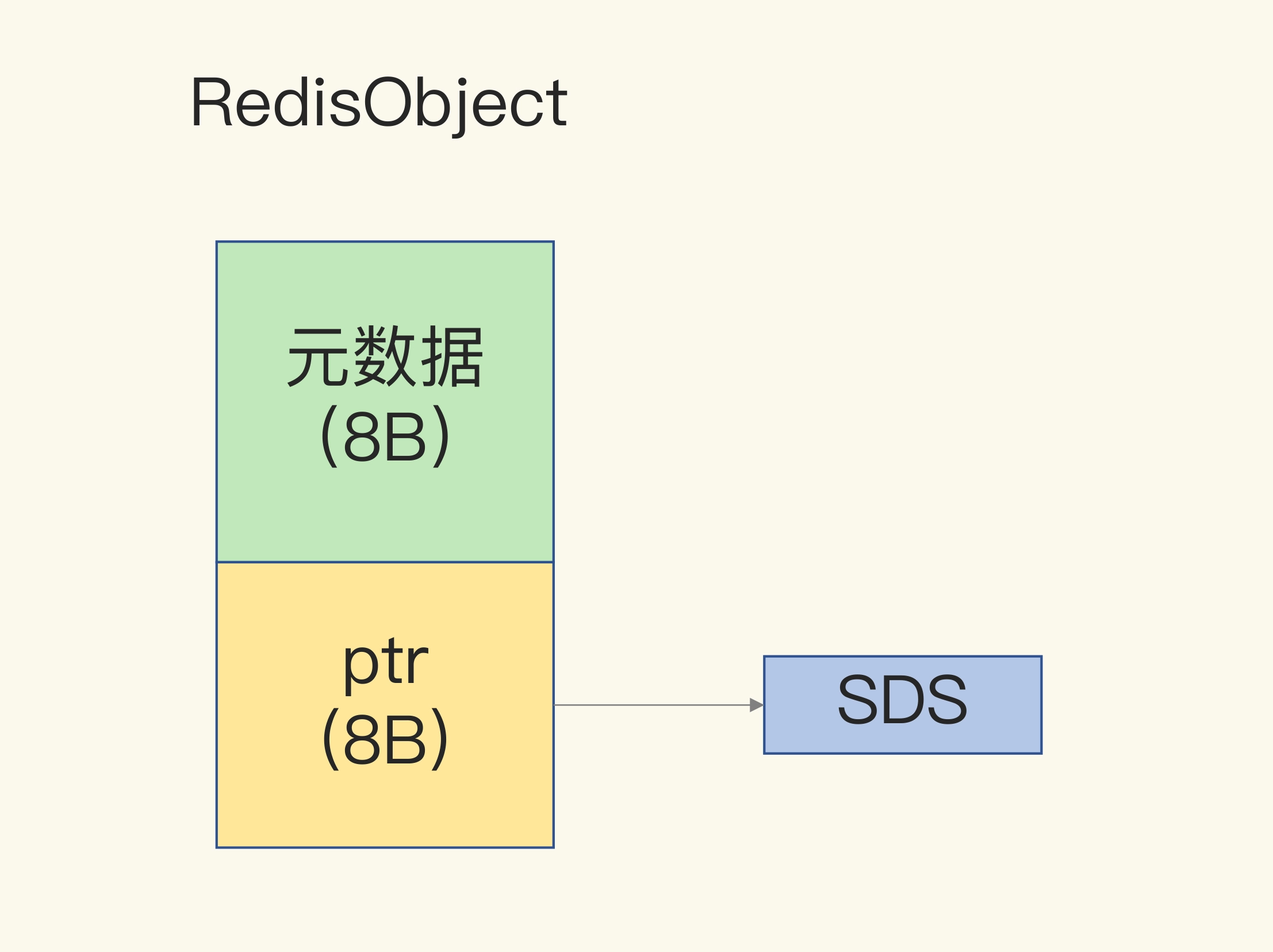
RedisObject 包含了 8 字节的元数据和一个 8 字节指针
内存碎片
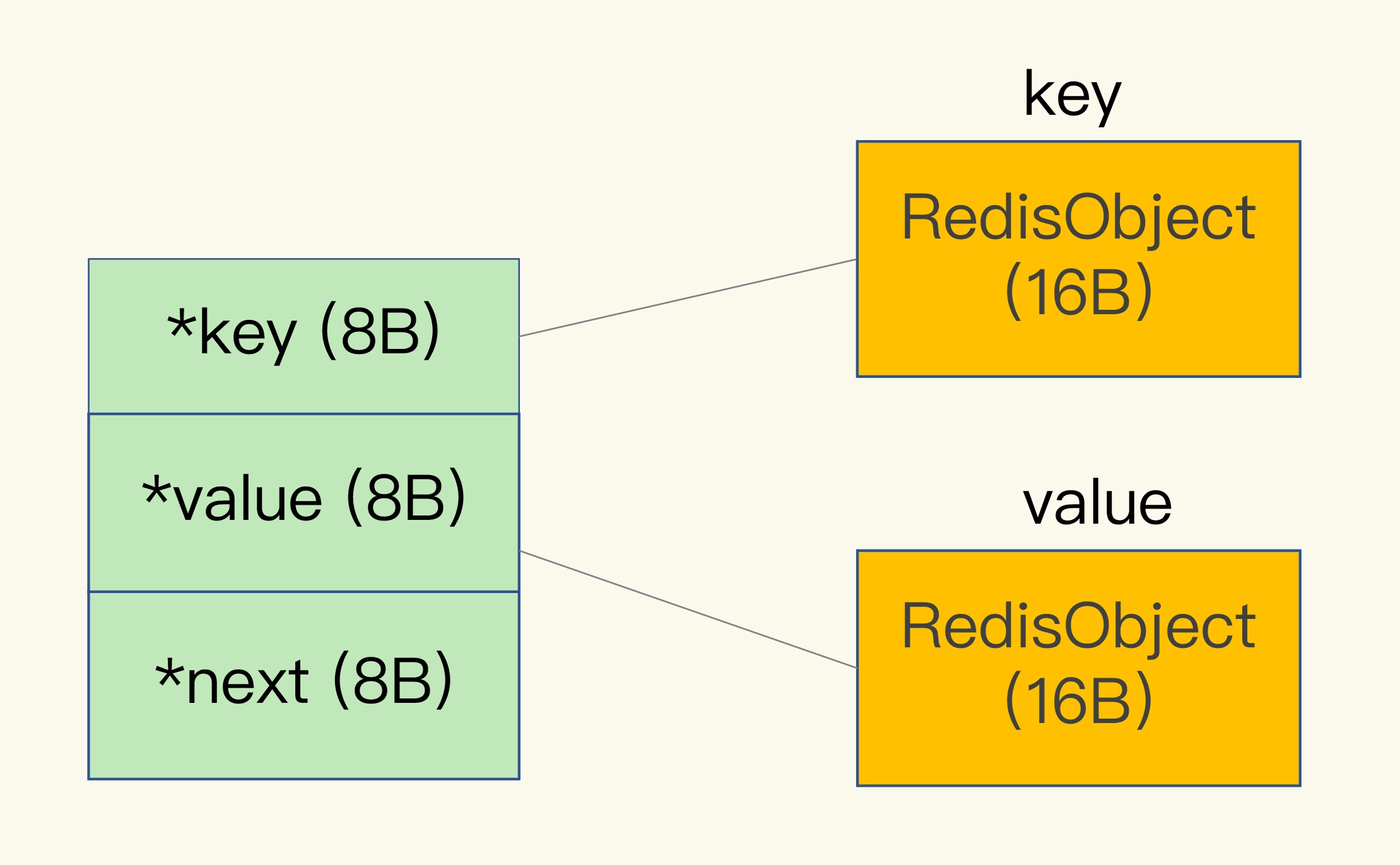
哈希表的每一项是一个 dictEntry 的结构体,用来指向一个键值对。dictEntry 结构中有三个 8 字节的指针,分别指向 key、value 以及下一个 dictEntry,三个指针共 24 字节
jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。
用什么数据结构可以节省内存?
Redis 有一种底层数据结构,叫压缩列表(ziplist),这是一种非常节省内存的结构。
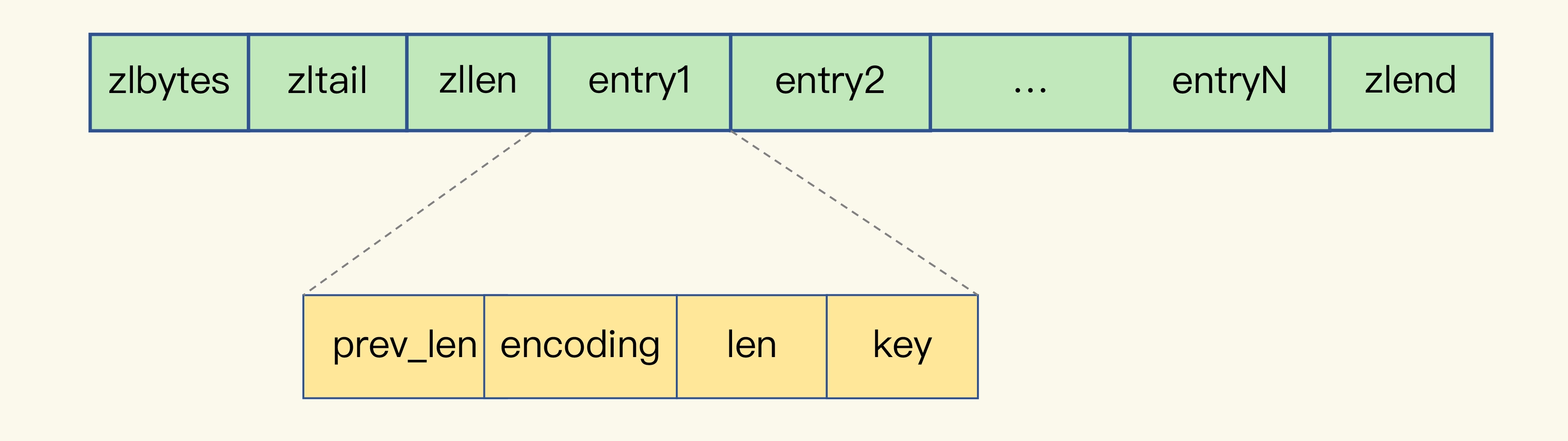
我们先回顾下压缩列表的构成。表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量,以及列表中的 entry 个数。压缩列表尾还有一个 zlend,表示列表结束。
压缩列表之所以能节省内存,就在于它是用一系列连续的 entry 保存数据。每个 entry 的元数据包括下面几部分。
- prev_len,表示前一个 entry 的长度。prev_len 有两种取值情况:1 字节或 5 字节。取值 1 字节时,表示上一个 entry 的长度小于 254 字节。虽然 1 字节的值能表示的数值范围是 0 到 255,但是压缩列表中 zlend 的取值默认是 255,因此,就默认用 255 表示整个压缩列表的结束,其他表示长度的地方就不能再用 255 这个值了。所以,当上一个 entry 长度小于 254 字节时,prev_len 取值为 1 字节,否则,就取值为 5 字节。
- len:表示自身长度,4 字节;
- encoding:表示编码方式,1 字节;
- content:保存实际数据。
如何用集合类型保存单值的键值对?
在保存单值的键值对时,可以采用基于 Hash 类型的二级编码方法。这里说的二级编码,就是把一个单值的数据拆分成两部分,前一部分作为 Hash 集合的 key,后一部分作为 Hash 集合的 value,这样一来,我们就可以把单值数据保存到 Hash 集合中了。
Hash 类型设置了用压缩列表保存数据时的两个阈值,一旦超过了阈值,Hash 类型就会用哈希表来保存数据了。
12 有一亿个keys要统计,应该用哪种集合?
聚合统计
1
SINTERSTORE user:id:rem user:id:20200803 user:id:20200804
你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计
排序统计
Sorted Set
二值状态统计
二值状态统计。这里的二值状态就是指集合元素的取值就只有 0 和 1 两种。
Bitmap
第一步,执行下面的命令,记录该用户 8 月 3 号已签到。
1
SETBIT uid:sign:3000:202008 2 1
第二步,检查该用户 8 月 3 日是否签到。
1
GETBIT uid:sign:3000:202008 2
第三步,统计该用户在 8 月份的签到次数。
1
BITCOUNT uid:sign:3000:202008
10 天连续签到的用户总数
Bitmap 支持用 BITOP 命令对多个 Bitmap 按位做“与”“或”“异或”的操作,操作的结果会保存到一个新的 Bitmap 中。

基数统计
网页 UV 的统计有个独特的地方,就是需要去重,一个用户一天内的多次访问只能算作一次
HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
HyperLogLog 的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。

13 GEO是什么?还可以定义新的数据类型吗?
面向 LBS 应用的 GEO 数据类型
14 如何在Redis中保存时间序列数据?
基于 Hash 和 Sorted Set 保存时间序列数据
Hash 类型有个短板:它并不支持对数据进行范围查询。
Sorted Set 范围查询
16 异步机制:如何避免单线程模型的阻塞?
Redis 实例有哪些阻塞点?
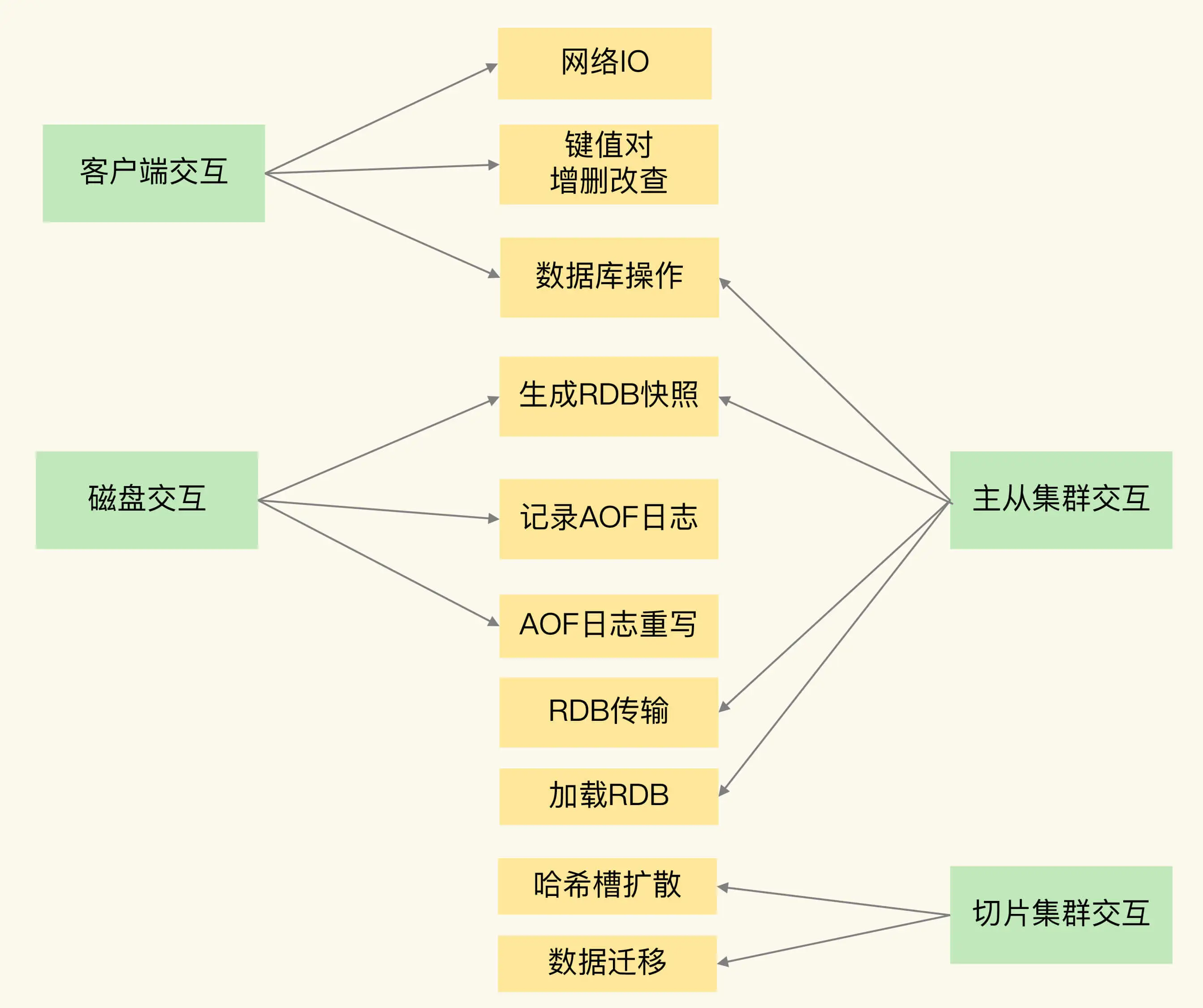
1. 和客户端交互时的阻塞点
作的复杂度是否为 O(N) 第一个阻塞点:集合全量查询和聚合操作。
如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞。
**bigkey 删除操作就是 Redis 的第二个阻塞点
第三个阻塞点:清空数据库**
2. 和磁盘交互时的阻塞点
AOF 日志时,会根据不同的写回策略对数据做落盘保存
3. 主从节点交互时的阻塞点
从库来说,它在接收了 RDB 文件后,需要使用 FLUSHDB 命令清空当前数据库
加载 RDB 文件就成为了 Redis 的第五个阻塞点
4. 切片集群实例交互时的阻塞点
17 为什么CPU结构也会影响Redis的性能?
多核 CPU 架构下,Redis 如果在不同的核上运行,就需要频繁地进行上下文切换
建议你在 Redis 运行时,把实例和某个核绑定
18 波动的响应延迟:如何应对变慢的Redis?(上)
Redis 自身操作特性的影响
1. 慢查询命令
- 用其他高效命令代替。比如说,如果你需要返回一个 SET 中的所有成员时,不要使用 SMEMBERS 命令,而是要使用 SSCAN 多次迭代返回,避免一次返回大量数据,造成线程阻塞。
- 当你需要执行排序、交集、并集操作时,可以在客户端完成,而不要用 SORT、SUNION、SINTER 这些命令,以免拖慢 Redis 实例。
2. 过期 key 操作
**频繁使用带有相同时间参数的 EXPIREAT 命令设置过期 key,这就会导致,在同一秒内有大量的 key 同时过期。
19 波动的响应延迟:如何应对变慢的Redis?(下)
20 删除数据后,为什么内存占用率还是很高?
当数据删除后,Redis 释放的内存空间会由内存分配器管理,并不会立即返回给操作系统
Redis 释放的内存空间可能并不是连续的,那么,这些不连续的内存空间很有可能处于一种闲置的状态。这就会导致一个问题:虽然有空闲空间,Redis 却无法用来保存数据,不仅会减少 Redis 能够实际保存的数据量,还会降低 Redis 运行机器的成本回报率。
什么是内存碎片?
内存碎片是如何形成的?
内因:内存分配器的分配策略
Redis 可以使用 libc、jemalloc、tcmalloc 多种内存分配器来分配内存,默认使用 jemalloc
jemalloc 的分配策略之一,是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节、48 字节,…, 2KB、4KB、8KB 等。当程序申请的内存最接近某个固定值时,jemalloc 会给它分配相应大小的空间。
外因:键值对大小不一样和删改操作
这些键值对会被修改和删除,这会导致空间的扩容和释放。具体来说,一方面,如果修改后的键值对变大或变小了,就需要占用额外的空间或者释放不用的空间。另一方面,删除的键值对就不再需要内存空间了,此时,就会把空间释放出来,形成空闲空间。
如何判断是否有内存碎片?
Redis 自身提供了 INFO 命令,可以用来查询内存使用的详细信息,命令如下:
1
2
3
4
5
6
7
8
INFO memory
# Memory
used_memory:1073741736
used_memory_human:1024.00M
used_memory_rss:1997159792
used_memory_rss_human:1.86G
…
mem_fragmentation_ratio:1.86
如何清理内存碎片?
- info memory 命令是一个好工具,可以帮助你查看碎片率的情况;
- 碎片率阈值是一个好经验,可以帮忙你有效地判断是否要进行碎片清理了;
- 内存碎片自动清理是一个好方法,可以避免因为碎片导致 Redis 的内存实际利用率降低,提升成本收益率。
21 缓冲区:一个可能引发“惨案”的地方
23 旁路缓存:Redis是如何工作的?
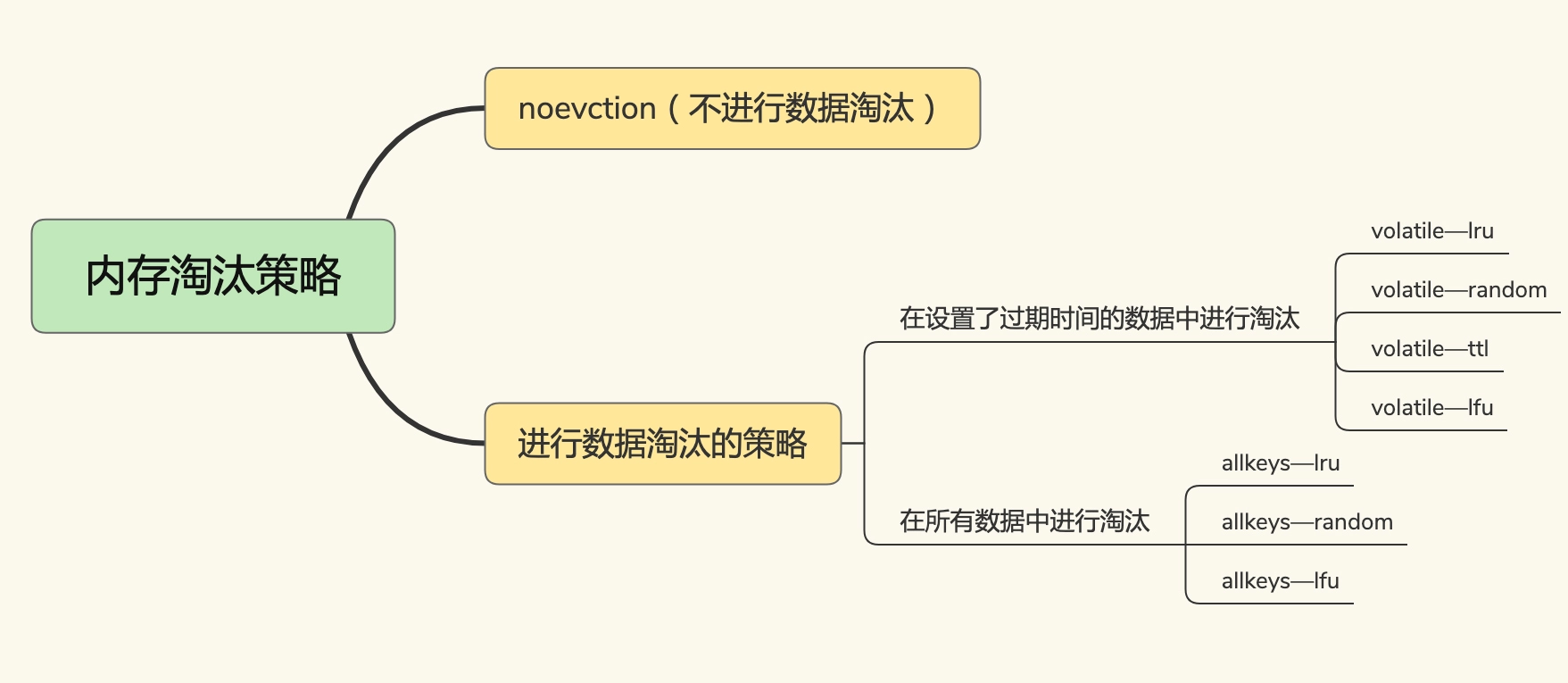
24 替换策略:缓存满了怎么办?
Redis 缓存有哪些淘汰策略?
25 缓存异常(上):如何解决缓存和数据库的数据不一致问题?
情况一:先删除缓存,再更新数据库。
情况二:先更新数据库值,再删除缓存值。
- 删除缓存值或更新数据库失败而导致数据不一致,你可以使用重试机制确保删除或更新操作成功。
- 在删除缓存值、更新数据库的这两步操作中,有其他线程的并发读操作,导致其他线程读取到旧值,应对方案是延迟双删。
26 缓存异常(下):如何解决缓存雪崩、击穿、穿透难题?
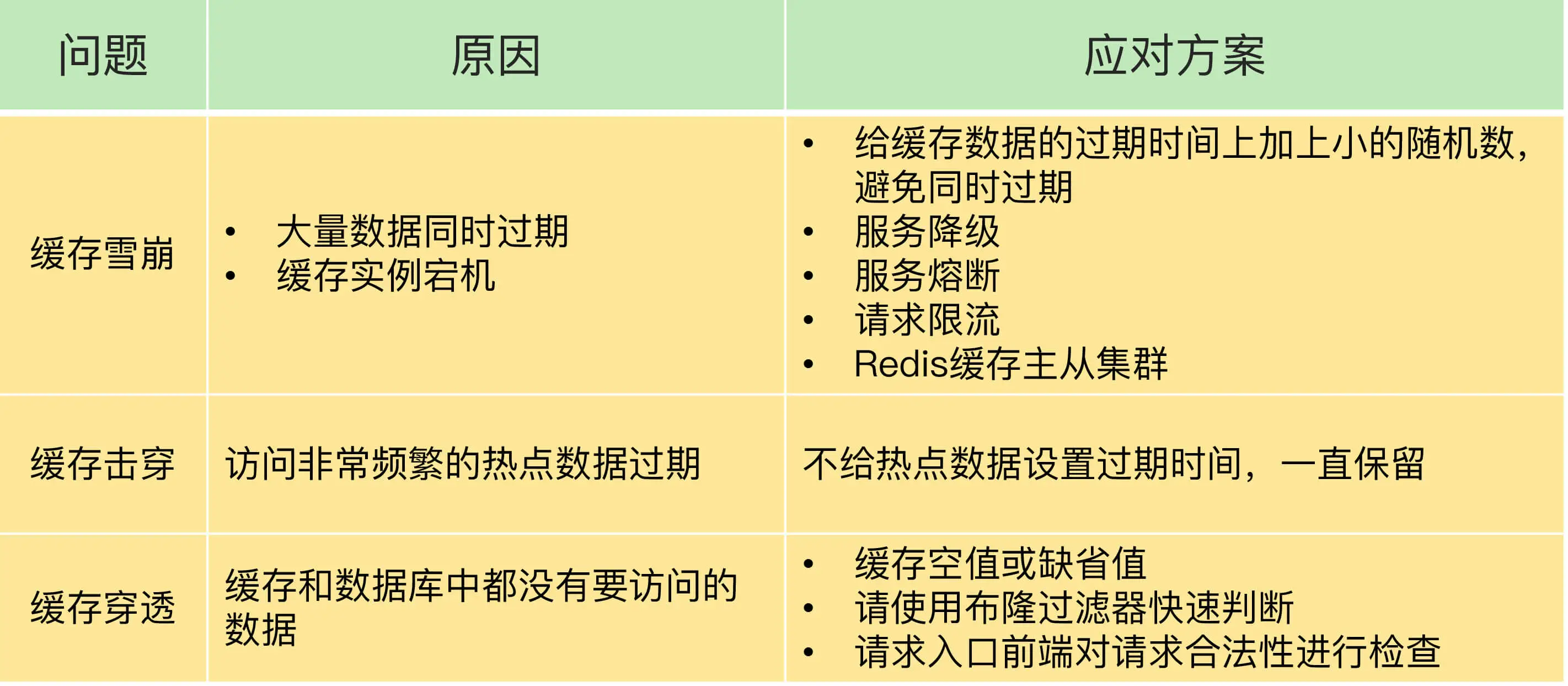
缓存雪崩
大量的应用请求无法在 Redis 缓存中进行处理
EXPIRE 命令给每个数据设置过期时间时,给这些数据的过期时间增加一个较小的随机数
是在业务系统中实现服务熔断或请求限流机制。
我给你的第二个建议就是事前预防。
过主从节点的方式构建 Redis 缓存高可靠集群
缓存击穿
热点数据 jvm内存
缓存穿透
第一种方案是,缓存空值或缺省值。
第二种方案是,使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
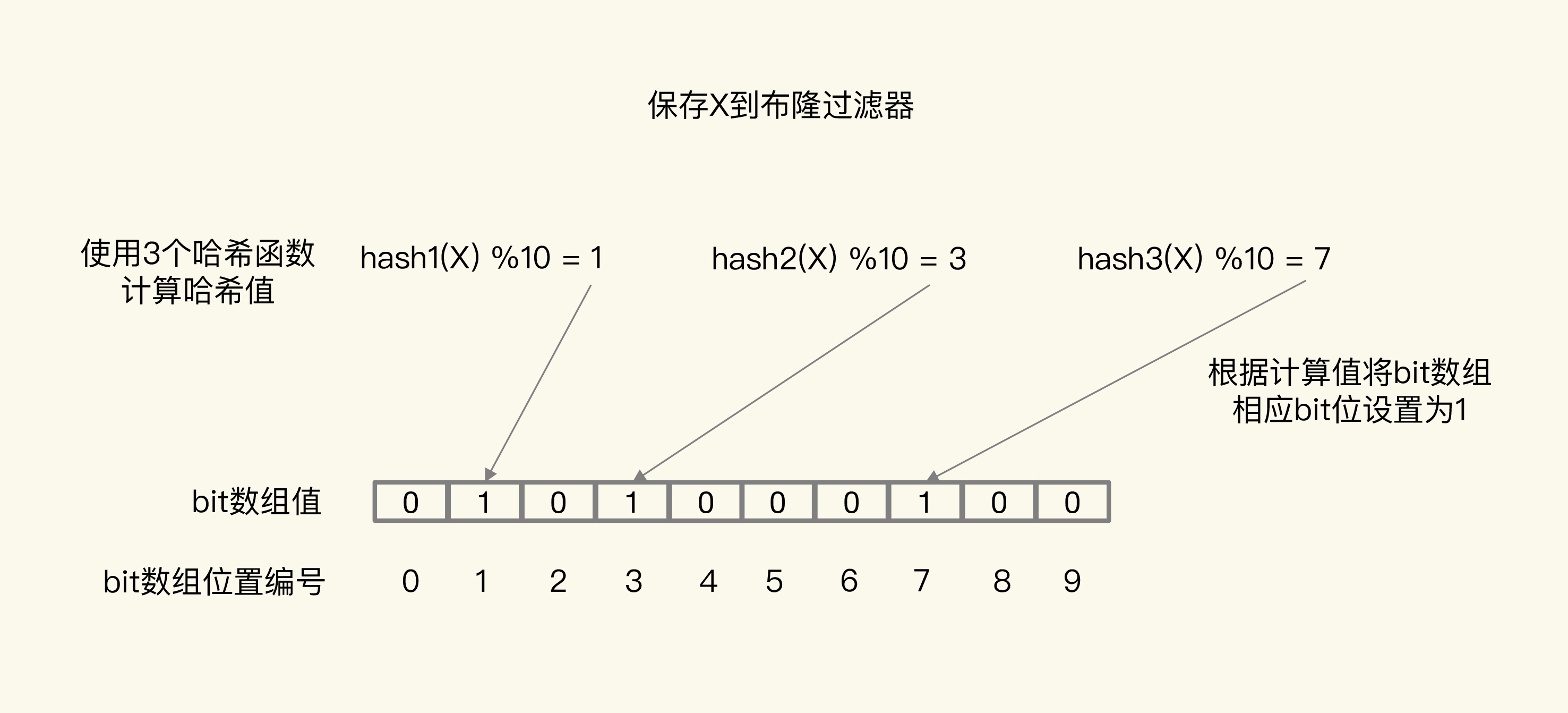
图中布隆过滤器是一个包含 10 个 bit 位的数组,使用了 3 个哈希函数,当在布隆过滤器中标记数据 X 时,X 会被计算 3 次哈希值,并对 10 取模,取模结果分别是 1、3、7。所以,bit 数组的第 1、3、7 位被设置为 1。当应用想要查询 X 时,只要查看数组的第 1、3、7 位是否为 1,只要有一个为 0,那么,X 就肯定不在数据库中。
27 缓存被污染了,该怎么办?
那什么是缓存污染呢?在一些场景下,有些数据被访问的次数非常少,甚至只会被访问一次。当这些数据服务完访问请求后,如果还继续留存在缓存中的话,就只会白白占用缓存空间。这种情况,就是缓存污染。
LRU 缓存策略
edis 中的 LRU 策略,会在每个数据对应的 RedisObject 结构体中设置一个 lru 字段,用来记录数据的访问时间戳。在进行数据淘汰时,LRU 策略会在候选数据集中淘汰掉 lru 字段值最小的数据(也就是访问时间最久的数据)。
LFU 缓存策略的优化
LFU 缓存策略是在 LRU 策略基础上,为每个数据增加了一个计数器,来统计这个数据的访问次数。当使用 LFU 策略筛选淘汰数据时,首先会根据数据的访问次数进行筛选,把访问次数最低的数据淘汰出缓存。如果两个数据的访问次数相同,LFU 策略再比较这两个数据的访问时效性,把距离上一次访问时间更久的数据淘汰出缓存。
Redis 在实现 LFU 策略的时候,只是把原来 24bit 大小的 lru 字段,又进一步拆分成了两部分。
- ldt 值:lru 字段的前 16bit,表示数据的访问时间戳;
- counter 值:lru 字段的后 8bit,表示数据的访问次数。
在实现 LFU 策略时,Redis 并没有采用数据每被访问一次,就给对应的 counter 值加 1 的计数规则,而是采用了一个更优化的计数规则。
简单来说,LFU 策略实现的计数规则是:每当数据被访问一次时,首先,用计数器当前的值乘以配置项 lfu_log_factor 再加 1,再取其倒数,得到一个 p 值;然后,把这个 p 值和一个取值范围在(0,1)间的随机数 r 值比大小,只有 p 值大于 r 值时,计数器才加 1。
下面这段 Redis 的部分源码,显示了 LFU 策略增加计数器值的计算逻辑。其中,baseval 是计数器当前的值。计数器的初始值默认是 5(由代码中的 LFU_INIT_VAL 常量设置),而不是 0,这样可以避免数据刚被写入缓存,就因为访问次数少而被立即淘汰。
1
2
3
4
double r = (double)rand()/RAND_MAX;
...
double p = 1.0/(baseval*server.lfu_log_factor+1);
if (r < p) counter++;
使用了这种计算规则后,我们可以通过设置不同的 lfu_log_factor 配置项,来控制计数器值增加的速度,避免 counter 值很快就到 255 了。
设计了一个 counter 值的衰减机制。
简单来说,LFU 策略使用衰减因子配置项 lfu_decay_time 来控制访问次数的衰减。LFU 策略会计算当前时间和数据最近一次访问时间的差值,并把这个差值换算成以分钟为单位。然后,LFU 策略再把这个差值除以 lfu_decay_time 值,所得的结果就是数据 counter 要衰减的值。
28 Pika:如何基于SSD实现大容量Redis?
SSD 来实现大容量的 Redis 实例。360 公司 DBA 和基础架构组联合开发的 Pika键值数据库
29 无锁的原子操作:Redis如何应对并发访问?
Redis 的两种原子操作方法
- 把多个操作在 Redis 中实现成一个操作,也就是单命令操作;INCR/DECR 命令
- 把多个操作写到一个 Lua 脚本中,以原子性方式执行单个 Lua 脚本。
别担心,Redis 提供了 INCR/DECR 命令,把这三个操作转变为一个原子操作了。INCR/DECR 命令可以对数据进行增值 / 减值操作,而且它们本身就是单个命令操作,Redis 在执行它们时,本身就具有互斥性。
30 如何使用Redis实现分布式锁?
1
SET key value [EX seconds | PX milliseconds] [NX]
1
2
3
4
5
6
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
Lua 脚本
基于多个 Redis 节点实现高可靠的分布式锁
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
这里的加锁操作和在单实例上执行的加锁操作一样,使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。
如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步是,一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
- 条件一:客户端从超过半数(大于等于 N/2+1)的 Redis 实例上成功获取到了锁;
- 条件二:客户端获取锁的总耗时没有超过锁的有效时间。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
在 Redlock 算法中,释放锁的操作和在单实例上释放锁的操作一样,只要执行释放锁的 Lua 脚本就可以了。这样一来,只要 N 个 Redis 实例中的半数以上实例能正常工作,就能保证分布式锁的正常工作了。
31 事务机制:Redis能实现ACID属性吗?
Redis 的事务机制能保证哪些属性?
原子性
- 命令入队时就报错,会放弃事务执行,保证原子性;
- 命令入队时没报错,实际执行时报错,不保证原子性;
- EXEC 命令执行时实例故障,如果开启了 AOF 日志,可以保证原子性。
一致性
在命令执行错误或 Redis 发生故障的情况下,Redis 事务机制对一致性属性是有保证的。
隔离性
基于WATCH机制
持久性
所以,不管 Redis 采用什么持久化模式,事务的持久性属性是得不到保证的。
Redis 的事务机制可以保证一致性和隔离性,但是无法保证持久性。
32 Redis主从同步与故障切换,有哪些坑?
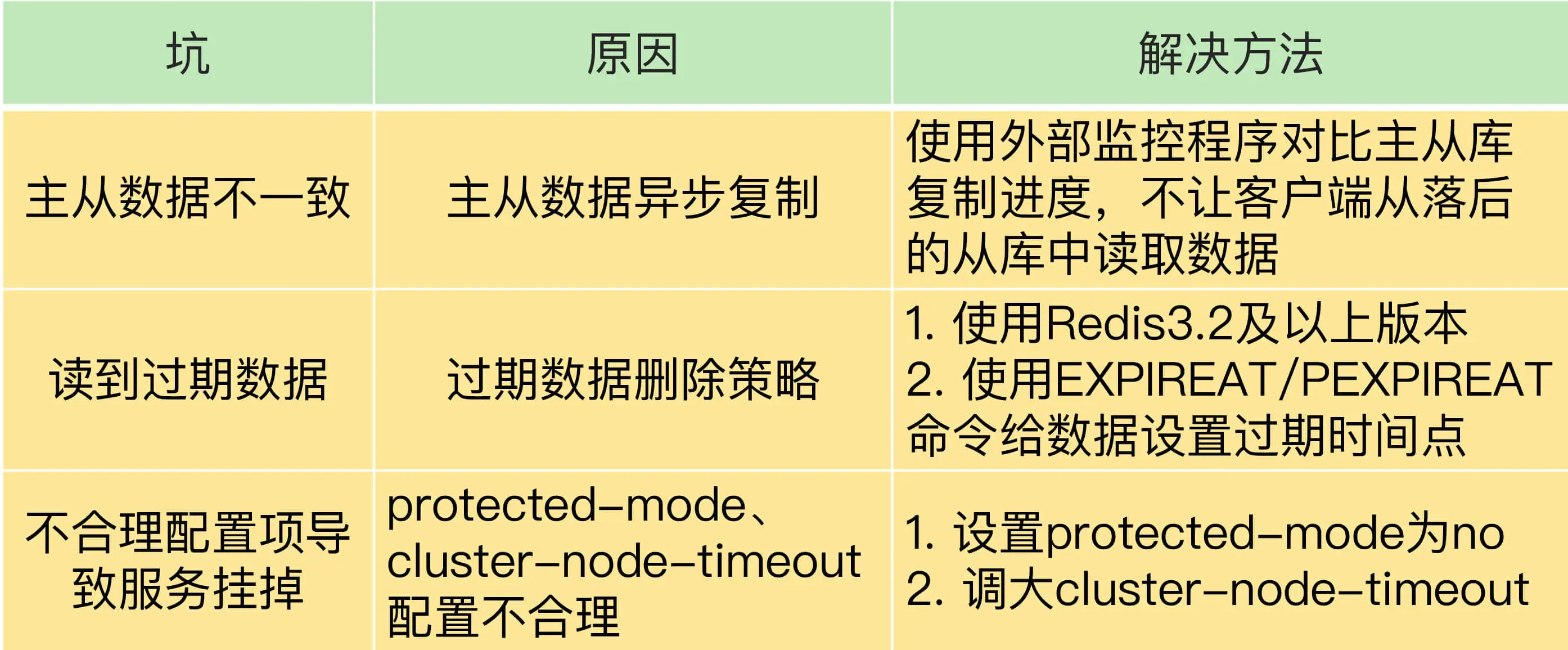
33 脑裂:一次奇怪的数据丢失
第一步:确认是不是数据同步出现了问题
在主从集群中发生数据丢失,最常见的原因就是主库的数据还没有同步到从库,结果主库发生了故障,等从库升级为主库后,未同步的数据就丢失了。
第二步:排查客户端的操作日志,发现脑裂现象
第三步:发现是原主库假故障导致的脑裂
在切换过程中,既然客户端仍然和原主库通信,这就表明,原主库并没有真的发生故障(例如主库进程挂掉)。我们猜测,主库是由于某些原因无法处理请求,也没有响应哨兵的心跳,才被哨兵错误地判断为客观下线的。结果,在被判断下线之后,原主库又重新开始处理请求了,而此时,哨兵还没有完成主从切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主库上写入数据了。
35 Codis VS Redis Cluster:我该选择哪一个集群方案?
36 Redis支撑秒杀场景的关键技术和实践都有哪些?
基于原子操作支撑秒杀场景
1
2
key: itemID
value: {total: N, ordered: M}
其中,itemID 是商品的编号,total 是总库存量,ordered 是已秒杀量。
1
2
3
4
5
6
7
8
9
10
11
12
#获取商品库存信息
local counts = redis.call("HMGET", KEYS[1], "total", "ordered");
#将总库存转换为数值
local total = tonumber(counts[1])
#将已被秒杀的库存转换为数值
local ordered = tonumber(counts[2])
#如果当前请求的库存量加上已被秒杀的库存量仍然小于总库存量,就可以更新库存
if ordered + k <= total then
#更新已秒杀的库存量
redis.call("HINCRBY",KEYS[1],"ordered",k) return k;
end
return 0
基于分布式锁来支撑秒杀场景
使用分布式锁来支撑秒杀场景的具体做法是,先让客户端向 Redis 申请分布式锁,只有拿到锁的客户端才能执行库存查验和库存扣减。
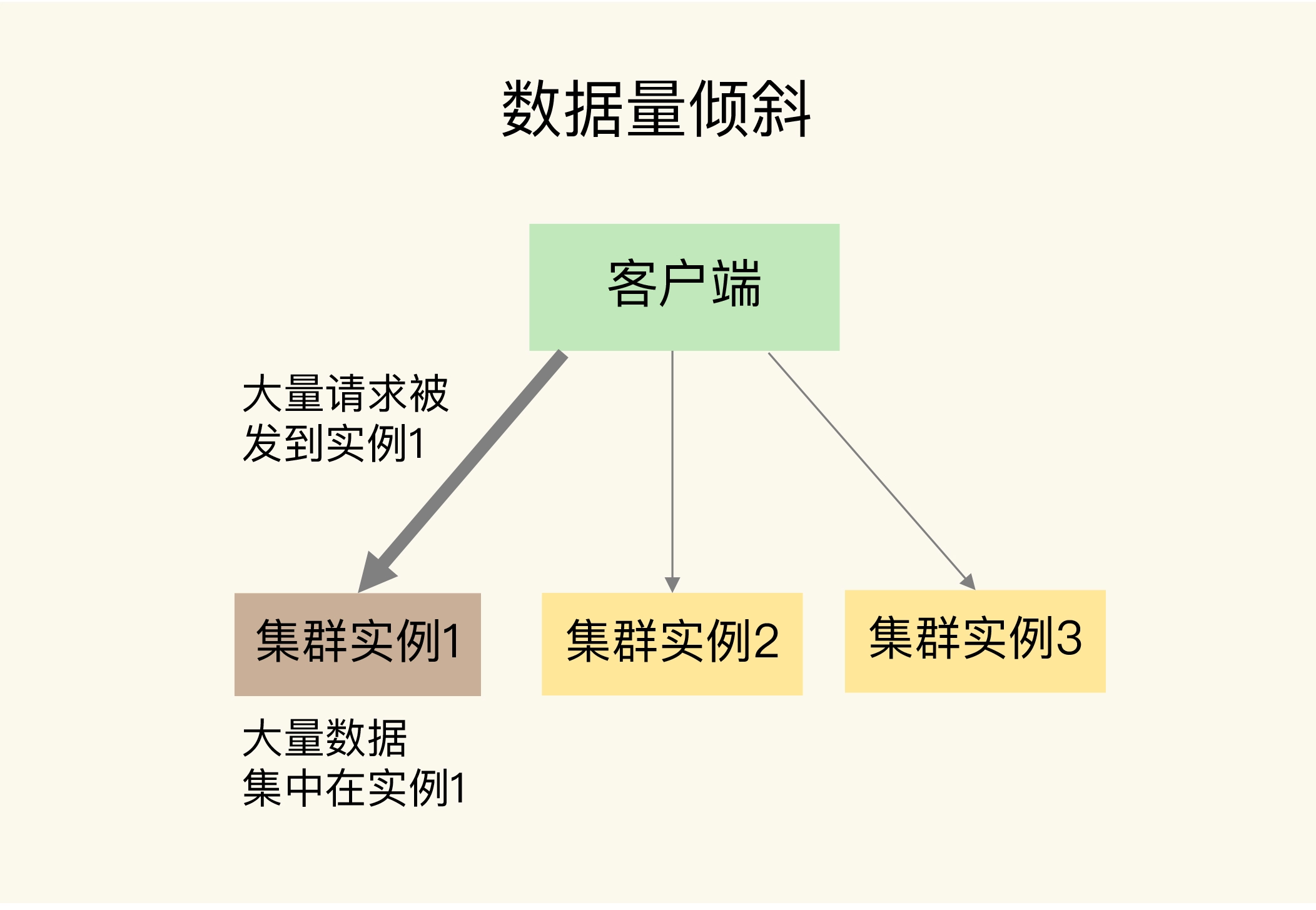
37 数据分布优化:如何应对数据倾斜?
数据量倾斜的成因和应对方法
bigkey 导致倾斜
一个根本的应对方法是,我们在业务层生成数据时,要尽量避免把过多的数据保存在同一个键值对中。
bigkey 正好是集合类型,我们还有一个方法,就是把 bigkey 拆分成很多个小的集合类型数据,分散保存在不同的实例上。
Slot 分配不均衡导致倾斜
集群运维人员没有均衡地分配 Slot
Hash Tag 导致倾斜
数据访问倾斜的成因和应对方法
热点数据既有多个副本可以同时服务请求