参考极客时间《消息队列高手课》 比较水
| 该如何选择消息队列?
1. RabbitMQ
生产者(Producer)和队列(Queue)之间增加了一个 Exchange 模块,你可以理解为交换机。
第一个问题是,RabbitMQ 对消息堆积的支持并不好
第二个问题是,RabbitMQ 的性能是我们介绍的这几个消息队列中最差的
最后一个问题是 RabbitMQ 使用的编程语言 Erlang
2. RocketMQ
RocketMQ 对在线业务的响应时延做了很多的优化,大多数情况下可以做到毫秒级的响应,如果你的应用场景很在意响应时延,那应该选择使用 RocketMQ。
RocketMQ 的一个劣势是,作为国产的消息队列,相比国外的比较流行的同类产品,在国际上还没有那么流行,与周边生态系统的集成和兼容程度要略逊一筹。
3. Kafka
Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域,几乎所有的相关开源软件系统都会优先支持 Kafka。
Kafka 这种异步批量的设计带来的问题是,它的同步收发消息的响应时延比较高,因为当客户端发送一条消息的时候,Kafka 并不会立即发送出去,而是要等一会儿攒一批再发送,在它的 Broker 中,很多地方都会使用这种“先攒一波再一起处理”的设计。当你的业务场景中,每秒钟消息数量没有那么多的时候,Kafka 的时延反而会比较高。所以,Kafka 不太适合在线业务场景。
如果说,消息队列并不是你将要构建系统的主角之一,你对消息队列功能和性能都没有很高的要求,只需要一个开箱即用易于维护的产品,我建议你使用 RabbitMQ。
如果你的系统使用消息队列主要场景是处理在线业务,比如在交易系统中用消息队列传递订单,那 RocketMQ 的低延迟和金融级的稳定性是你需要的。
如果你需要处理海量的消息,像收集日志、监控信息或是前端的埋点这类数据,或是你的应用场景大量使用了大数据、流计算相关的开源产品,那 Kafka 是最适合你的消息队列。
RocketMQ 的消息模型
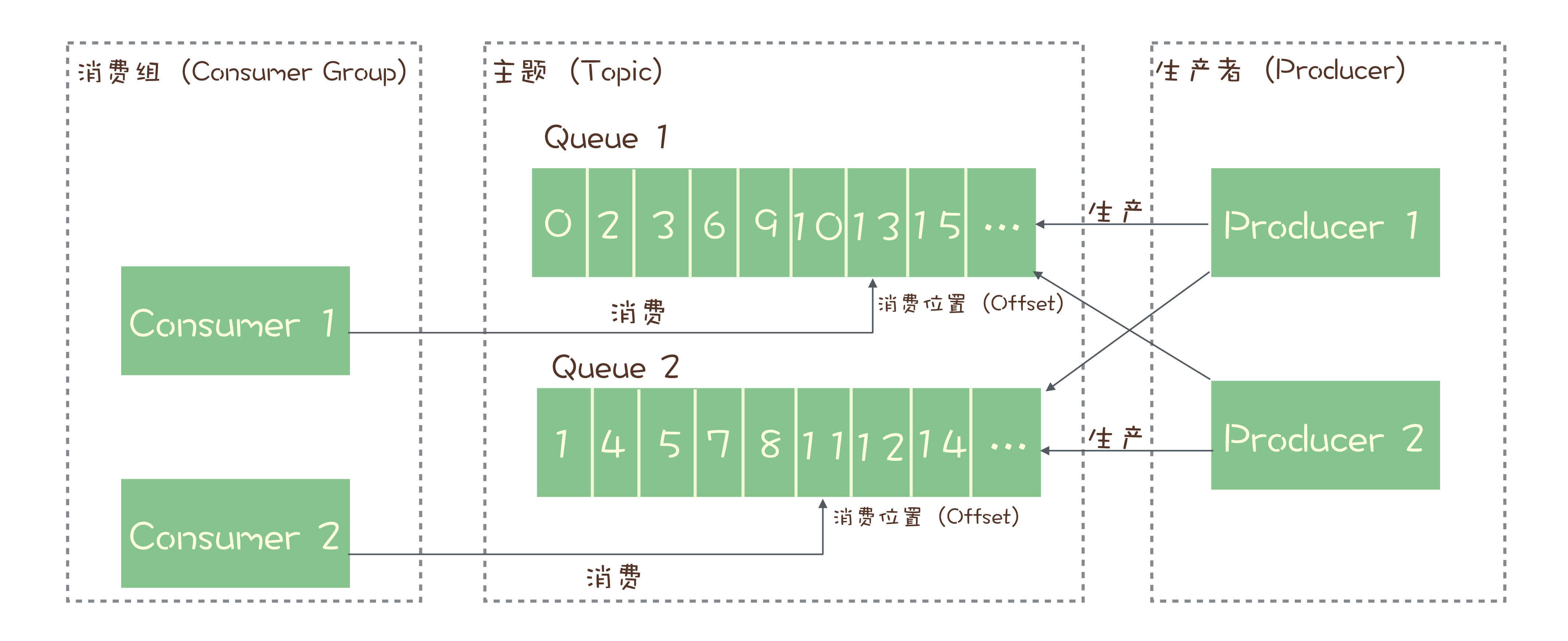
在任何一个时刻,某个queue在同一个consumer group中最多只能有一个consumer占用。
每个主题包含多个队列,通过多个队列来实现多实例并行生产和消费。需要注意的是,RocketMQ 只在队列上保证消息的有序性,主题层面是无法保证消息的严格顺序的。
RocketMQ 中,订阅者的概念是通过消费组(Consumer Group)来体现的。每个消费组都消费主题中一份完整的消息,不同消费组之间消费进度彼此不受影响,也就是说,一条消息被 Consumer Group1 消费过,也会再给 Consumer Group2 消费。
消费组中包含多个消费者,同一个组内的消费者是竞争消费的关系,每个消费者负责消费组内的一部分消息。如果一条消息被消费者 Consumer1 消费了,那同组的其他消费者就不会再收到这条消息。
在 Topic 的消费过程中,由于消息需要被不同的组进行多次消费,所以消费完的消息并不会立即被删除,这就需要 RocketMQ 为每个消费组在每个队列上维护一个消费位置(Consumer Offset),这个位置之前的消息都被消费过,之后的消息都没有被消费过,每成功消费一条消息,消费位置就加一。这个消费位置是非常重要的概念,我们在使用消息队列的时候,丢消息的原因大多是由于消费位置处理不当导致的。
Kafka 的消息模型
在 Kafka 中,队列这个概念的名称不一样,Kafka 中对应的名称是“分区(Partition)”
分布式事务

| 如何确保消息不会丢失?
- 在生产阶段,你需要捕获消息发送的错误,并重发消息。
- 在存储阶段,你可以通过配置刷盘和复制相关的参数,让消息写入到多个副本的磁盘上,来确保消息不会因为某个 Broker 宕机或者磁盘损坏而丢失。
- 在消费阶段,你需要在处理完全部消费业务逻辑之后,再发送消费确认。
| 消息积压了该如何处理?
-
所以,我们在设计系统的时候,一定要保证消费端的消费性能要高于生产端的发送性能,这样的系统才能健康的持续运行。
-
消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。特别需要注意的一点是,在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的。如果 Consumer 的实例数量超过分区数量,这样的扩容实际上是没有效果的。原因我们之前讲过,因为对于消费者来说,在每个分区上实际上只能支持单线程消费。
-
在收到消息的 OnMessage 方法中,不处理任何业务逻辑,把这个消息放到一个内存队列里面就返回了。然后它可以启动很多的业务线程,这些业务线程里面是真正处理消息的业务逻辑,这些线程从内存队列里取消息处理,这样它就解决了单个 Consumer 不能并行消费的问题。
| Kafka如何实现高性能IO
- 使用批量处理的方式来提升系统吞吐能力。
- 基于磁盘文件高性能顺序读写的特性来设计的存储结构。
- 利用操作系统的 PageCache 来缓存数据,减少 IO 并提升读性能。
- 使用零拷贝技术加速消费流程。
| 数据压缩:时间换空间的游戏
- 不压缩直接传输需要的时间是: 传输未压缩数据的耗时。
- 使用数据压缩需要的时间是: 压缩耗时 + 传输压缩数据耗时 + 解压耗时。
在开启压缩时,Kafka 选择一批消息一起压缩,每一个批消息就是一个压缩分段。使用者也可以通过参数来控制每批消息的大小。
Kafka和RocketMQ的消息复制实现
RocketMq Dledger
Dledger 在写入消息的时候,要求至少消息复制到半数以上的节点之后,才给客户端返回写入成功,并且它是支持通过选举来动态切换主节点的。