倒排索引:ES倒排索引底层原理及FST算法的实现过程_es倒排索引原理_Elastic开源社区的博客-CSDN博客
| [关于Lucene的词典FST深入剖析 | 申艳超-博客](https://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/) |
Elasticsearch
Elasticsearch是一个基于Apache Lucene(TM)的分布式可扩展的实时搜索和分析引擎.
优点:
实时分析的分布式搜索引擎,效率极高
可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据
它是一个面向文档的数据库,既然是数据库那就来说一下它和数据库的对应关系:
关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch(非关系型数据库) ⇒ 索引(index) ⇒ 类型(type) ⇒ 文档 (document)⇒ 字段(Fields)

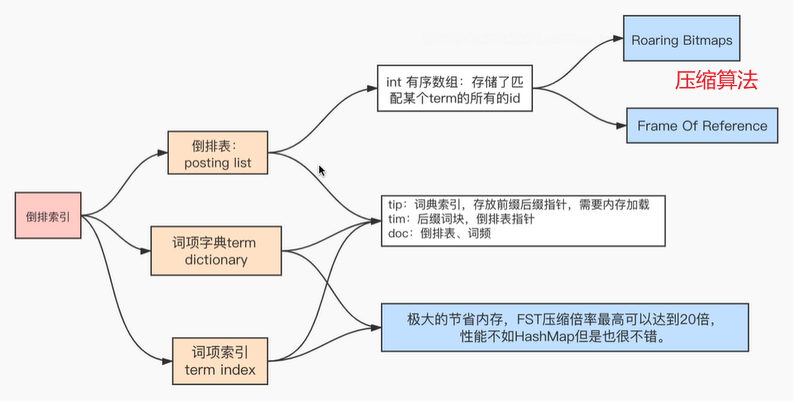
1. 倒排索引
1.1 数据结构
-
倒排表:包含某个词项的所有id的数据存储了在.doc文件中;倒排表的文件结构,其内部存储了包含Term的id数组、词频、postion、payload、offset等信息,需要重点注意的是ES内部采用怎样的压缩算法
-
词项字典:包含了index field的所有经过normalization token filters处理之后的词项数据,最终存储在.tim文件中。normalization其实是一个如去重、时态统一、大小写统一、近义词处理等类似的相关操作
-
词项索引:就是为了加速词项字典检索的一种数据结构,落地文件为.tip
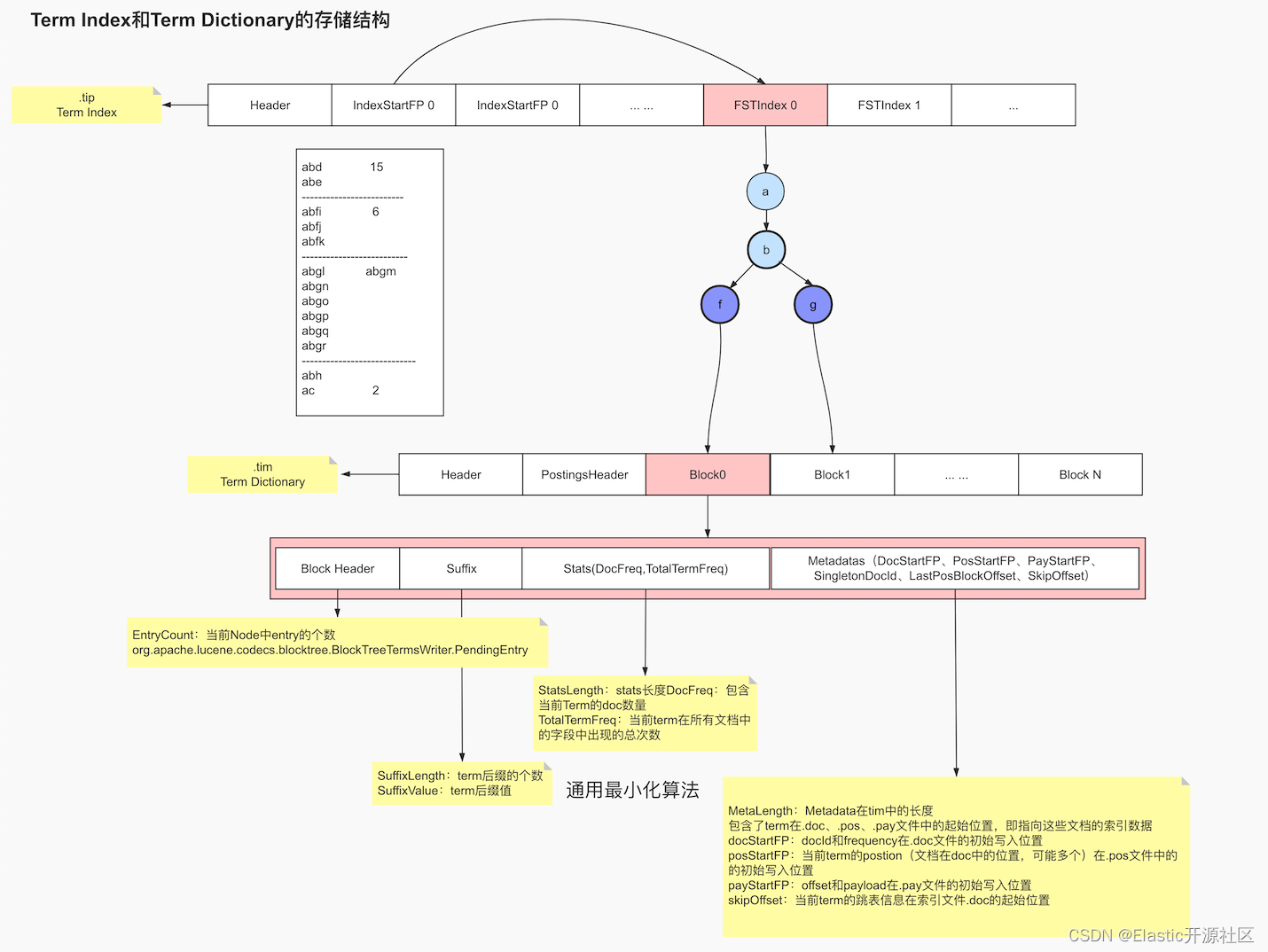
1.2 Term Index 词项索引
B-Tree通过减少磁盘寻道次数来提高查询性能,Elasticsearch也是采用同样的思路,直接通过内存查找term,不读磁盘,但是如果term太多,term dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪页,可以理解term index是一颗树:
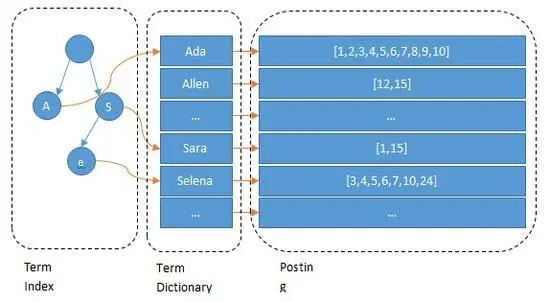
词项索引 词项字典 倒排表
term index不需要存下所有的term,而仅仅是他们的一些前缀与Term Dictionary的block之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
1.3 FST原理简析
| 参见[关于Lucene的词典FST深入剖析 | 申艳超-博客](https://www.shenyanchao.cn/blog/2018/12/04/lucene-fst/) |
倒排索引:ES倒排索引底层原理及FST算法的实现过程_es倒排索引原理_Elastic开源社区的博客-CSDN博客
1.4 倒排表的压缩算法
分词对应的数组 Posting List 实际就是一个个有序数组,而有序数值数组是比较容易进行压缩处理的,而且一般来说压缩效益也不错,如果能对其进行压缩是能够大大节约空间资源的
ES 中倒排索引的压缩算法主要有 FOR 算法(Frame Of Reference)和 RBM 算法(RoaringBitMap)
1.4.1 FOR
FOR 算法的核心思想是用减法来削减数值大小,从而达到降低空间存储。 假设 V(n)表示数组中第 n 个字段的值,那么经过 FOR 算法压缩的数值 V(n)=V(n)-V(n-1)。也就是说存储的是后一位减去前一位的差值。存储是也不再按照 int 来计算了,而是看这个数组的最大值需要占用多少 bit 来计算

我们按照差值计算的方式来保存数据,初始值为 1,2 与 1 的差值为 1,3 与 2 的差值为 1……最终我们就将原始 Posting List 数据转化为 100 万个 1,每个 1 我们可以用 1bit 来记录,总空间=1bit✖100 万=100 万 bit,相比原有 400 万 Byte=3200bit,空间压缩了 32 倍

在实际生产中,不可能出现一个 term 的 Posting List 是这种差值均为 1 的情况,所以我们以通用示例举例。假如原数据为[73,300,302,332,343,372],数组中 6 个数字占据总空间为 24 字节。按照差值方式记录,数组转化为[73,227,2,30,11,29],最大数字为 227,大于 2 的 7 次方 128,小于 2 的 8 次方 256,所以每个数字可以使用 8bit 即 1Byte 来保存,占据总空间为 1Byte*6 + 1Byte=7Byte
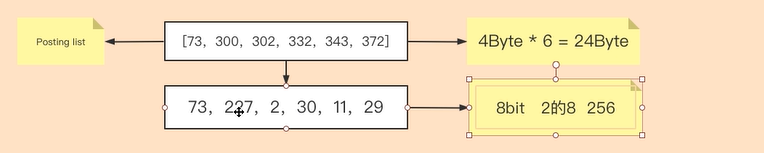
在此基础上,我们将差值数组按照密集度划分为[73,227]和[2,30,11,29],其中[73,227]中最大值 227 介于 2 的 7 次方和 2 的 8 次方之间,所以用 8bit=1Byte 作为切割分段,[2,30,11,29]中最大数 30 介于 2 的 4 次方和 2 的 5 次方之间,所以用 5bit 作为切割分段。
数组[73,227]占据总空间为 8bit✖2 个=16bit=2Byte
数组[2,30,11,29]占据总空间为 5bit✖4 个=20bit=3Byte
所以,最终占据总空间=1+2+1+3=7Byte
1.4.2 RBM
FOR 压缩算法,算法核心是将 PostingList 按照差值密集度转化成两个差值数组。在这里我们要考虑一种情况就是:在大数据中,10 亿条数据分词 500 万个,如果分词“小米”所在 PostList 比较分散且差值很大,此时使用 FOR 算法效果就会大打折扣。所以稀疏的数组,不适合使用 FOR 算法

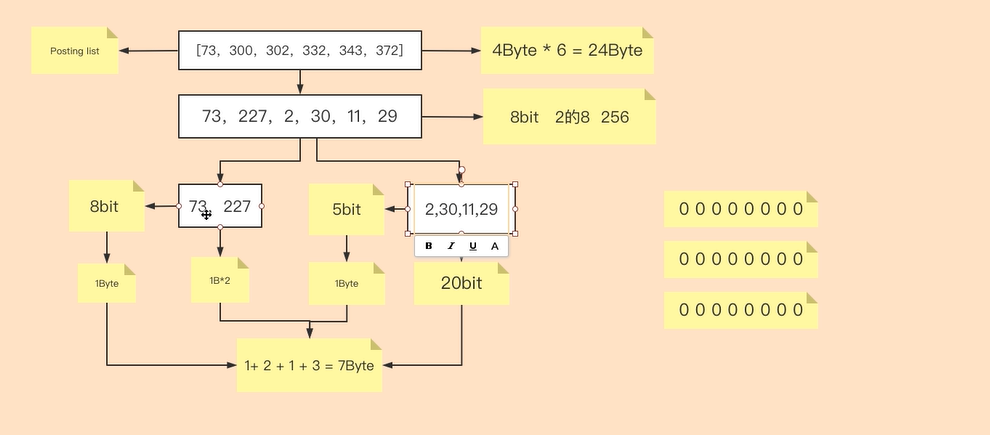
源数据 PostingList 是由 int 类型组成的数组,int 类型=4Byte=32bit,最大值=2 的 32 次方-1=4294967295≈43 亿。当数据较大且稀疏时,我们将 32bit 拆分为 16bit 和 16bit,16bit 最大值=65535,前 16bit 存放商,后 16bit 存放余数,所以商和余数都不会超过 65535.我们将源数组的值除以 65536,得到的商和余数分别存放在前 16bit 和后 16bit。
以数字 196658 为例,转化为 2 进制,前 16 位=3,后 16 位=50
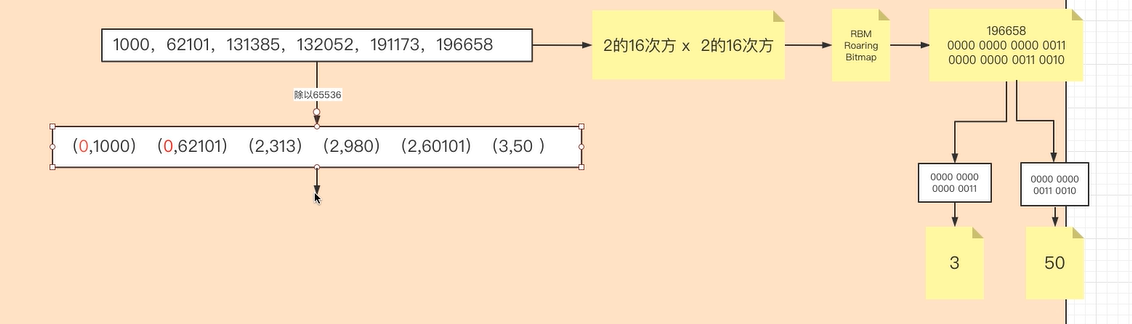
得到的结果以 K-V 存放。Key 最大值为 16bit,所以以 short[]数组存放,Value 以 Container 存放。
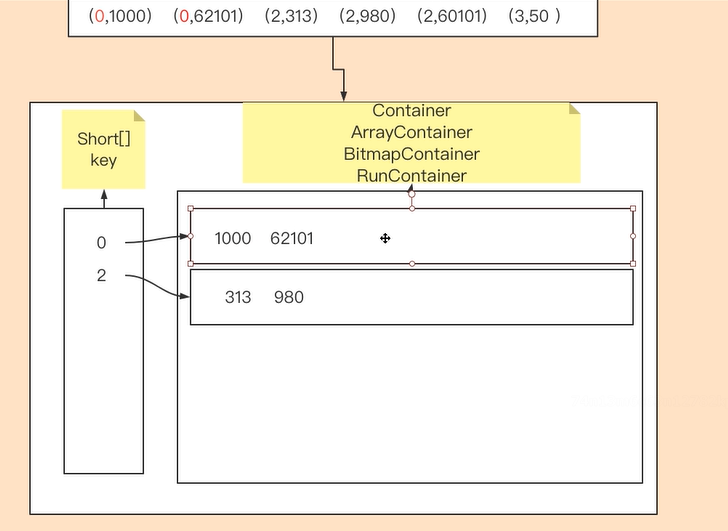
通过看 Container 源码,我们可以看到 Container 有 3 种:ArrayContainer、BitmapContainer、RunContainer。
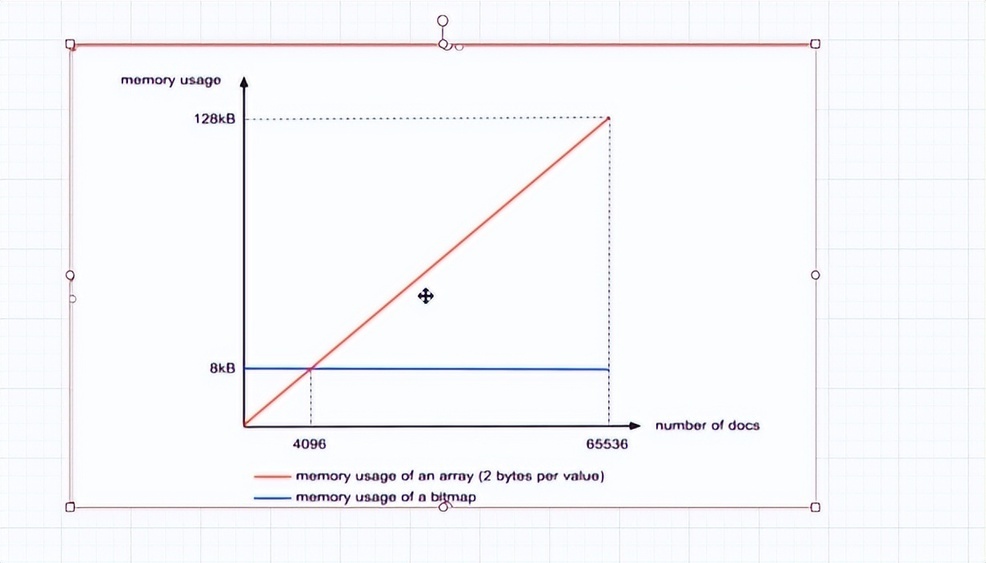
- ArrayContainer 本质为集合,所以随着数组中数量越多,占用空间越多,呈正向增长。
当数组种数量为 4096 时,占据总空间=4096 个✖16bit(即 2Byte)➗1024=8KB
当数组种数量为 65536 时,占据总空间=65536 个✖16bit(即 2Byte)➗1024=128KB
- BitmapContainer 位图,核心就是将原有存储数值转化成该数值在哪个位置上存在
由于余数最大值为 65535,所以我们需要 65536 位位图,数值是多少,在位图上对应的位置就是多少。数值等于 4096,则位图上 4096 位值为 1;数值等于 65535,则位图上 65535 位值为 1。每个位置上的数都占用 8KB 空间(8KB=65536bit)
由于余数最大值为 65535,所以我们需要 65536 位位图,数值是多少,在位图上对应的位置就是多少。数值等于 4096,则位图上 4096 位值为 1;数值等于 65535,则位图上 65535 位值为 1。每个位置上的数都占用 8KB 空间(8KB=65536bit)
综上所述,Elasticsearch提高检索效率的方式为:
1、将磁盘里的东西尽量搬到内存,减少磁盘随机读取次数;
2、结合各种奇特的压缩算法,用及其苛刻的态度使用内存。
2 DSL
DLS-Query查询
Query Context:会对搜索进行相关性算分
term
term是代表完全匹配,也就是精确查询,搜索前不会再对搜索词进行分词拆解。
match
match进行搜索的时候,会先进行分词拆分,拆完后,再来匹配
multi_match
match_phrase
短语搜索,要求所有的分词必须同时出现在文档中,同时位置必须紧邻一致。
DLS-Filter查询
Filter Context:不需要相关性算分,能够利用缓存来获得更好的性能
bool.filter关键字
ES基本数据类型
字符串: text 和 keyword。 在存储的时的区别。 text: 是会被分词器来拆分的,拆分后倒排索引,不能用作排序和聚合。 keyword: 属性算作一个整体,不会被分词器拆开。
数值型: long、integer、short、byte、double、float
日期型: date
布尔型: boolean
ES这些类型是可以在我们去存放数据的时候,动态映射的,也可以类似关系数据库,去指定字段名和字段数据类型。
3 相关度评分算法
TF/IDF评分公式
TF
词频、逆文档频率,词项权重、长度范数
TF Score = 某个词在文档中出现的次数 / 文档的长度
举例:某文档 D,长度为 200,其中 “Lucence” 出现了 2 次,“的” 出现了 20 次,“原理” 出现了 3 次,那么:
TF(Lucence D) = 2/200 = 0.01
TF(的 D) = 20/200 = 0.1
TF(原理 D) = 3/200 = 0.015
“Lucence 的原理” 这个短语与文档 D 的相关性就是三个词的相关性之和。
TF(Lucence的原理 D) = 0.01 + 0.1 + 0.015 = 0.125
IDF
假设关键词 w 在 n 个文档中出现过,那么 n 越大,则 w 的权重越小。常用的方法叫 “逆文本频率指数”(Inverse Dcument Frequency, 缩写为 IDF)。

BM25, 下一代的 TF-IDF
BM25 中的 TF
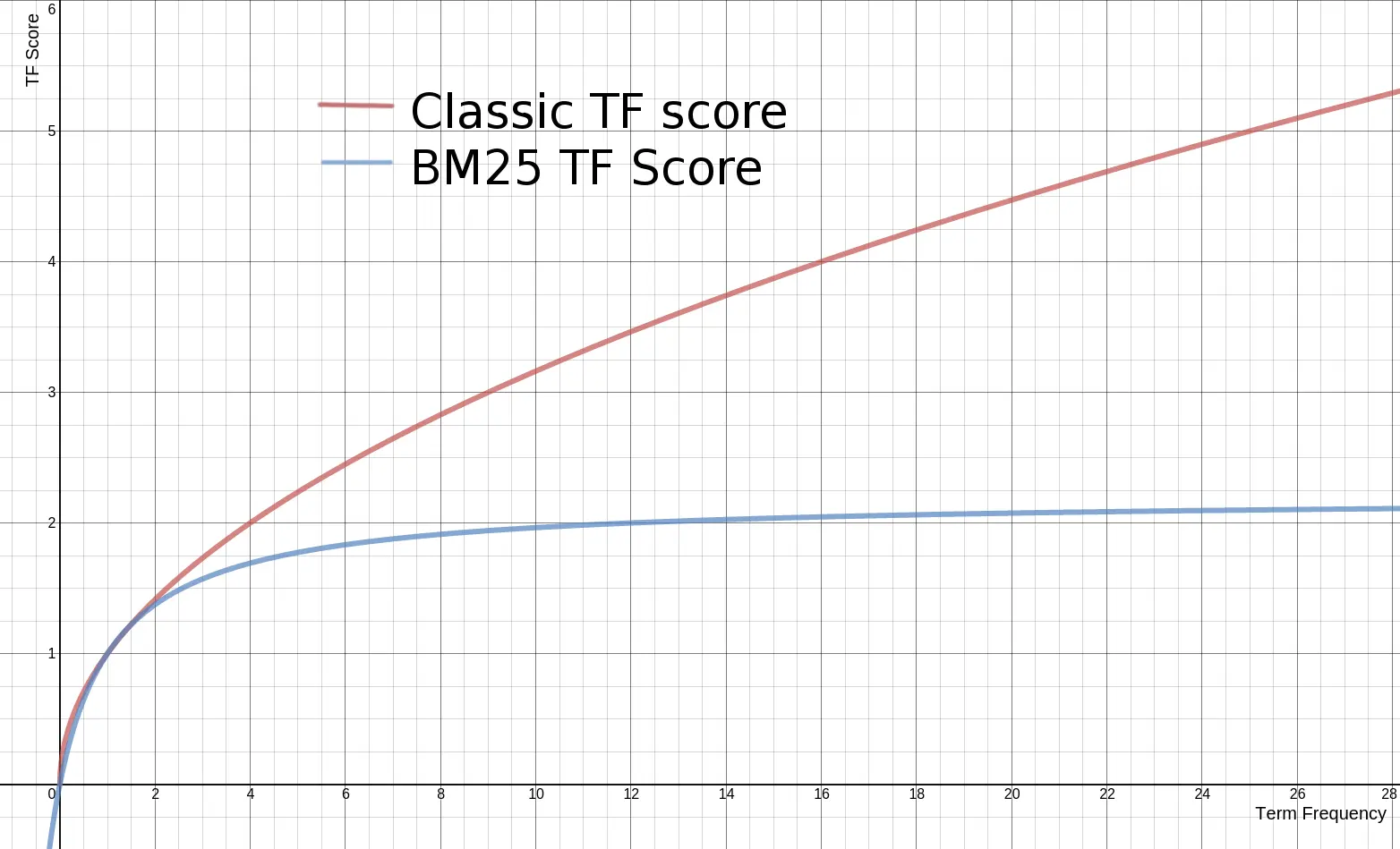
传统的 TF 值理论上是可以无限大的。而 BM25 与之不同,它在 TF 计算方法中增加了一个常量 k,用来限制 TF 值的增长极限。
传统 TF Score = sqrt(tf) BM25的 TF Score = ((k + 1) * tf) / (k + tf)
BM25 如何对待文档长度
BM25 还引入了平均文档长度的概念,单个文档长度对相关性的影响力与它和平均长度的比值有关系。BM25 的 TF 公式里,除了 k 外,引入另外两个参数:L 和 b。L 是文档长度与平均长度的比值。如果文档长度是平均长度的 2 倍,则 L=2。b 是一个常数,它的作用是规定 L 对评分的影响有多大。加了 L 和 b 的公式变为:
TF Score = ((k + 1) * tf) / (k * (1.0 - b + b * L) + tf)
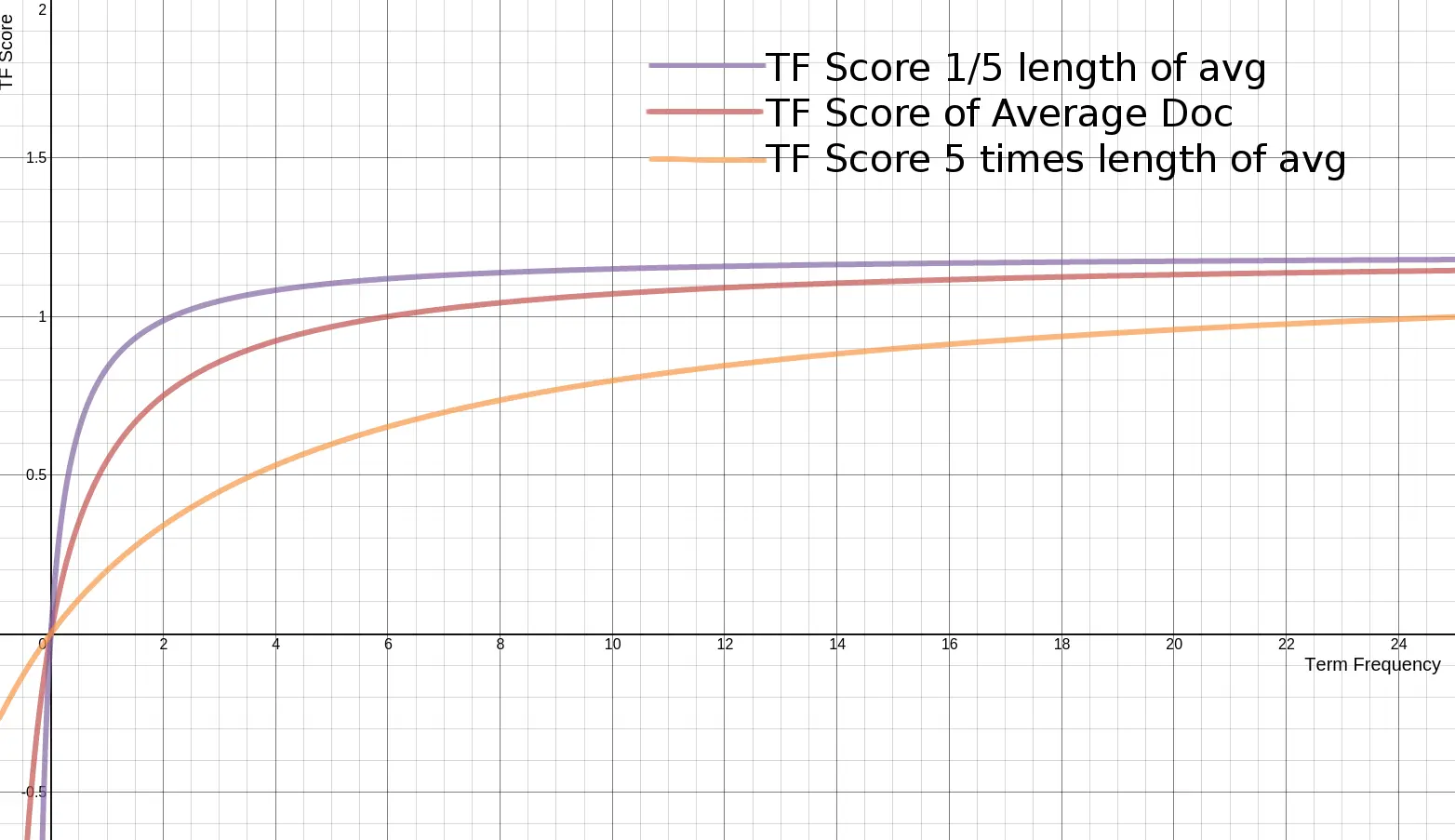
文档越短,它逼近上限的速度越快,反之则越慢。
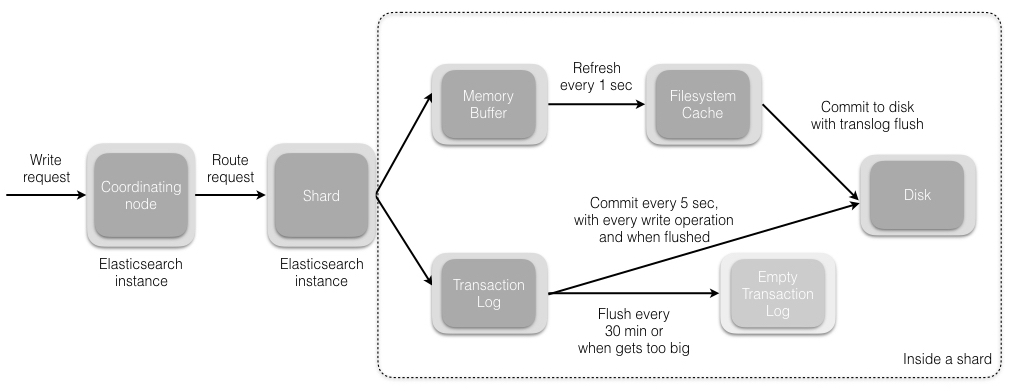
4 剖析写操作
当我们发送索引一个新文档的请求到协调节点后,将发生如下一组操作:
- Elasticsearch 集群中的每个节点都包含了改节点上分片的元数据信息。协调节点 (默认) 使用文档 ID 参与计算,以便为路由提供合适的分片。Elasticsearch 使用 MurMurHash3 函数对文档 ID 进行哈希,其结果再对分片数量取模,得到的结果即是索引文档的分片。
shard = hash(document_id) % (num_of_primary_shards)
- 当分片所在的节点接收到来自协调节点的请求后,会将该请求写入 translog 并将文档加入内存缓冲。如果请求在主分片上成功处理,该请求会并行发送到该分片的副本上。当 translog 被同步 (fsync) 到全部的主分片及其副本上后,客户端才会收到确认通知。
- 内存缓冲会被周期性刷新 (默认是 1 秒),内容将被写到文件系统缓存的一个新段上。虽然这个段并没有被同步 (fsync),但它是开放的,内容可以被搜索到。
- 每 30 分钟,或者当 translog 很大的时候,translog 会被清空,文件系统缓存会被同步。这个过程在 Elasticsearch 中称为冲洗 (flush)。在冲洗过程中,内存中的缓冲将被清除,内容被写入一个新段。段的 fsync 将创建一个新的提交点,并将内容刷新到磁盘。旧的 translog 将被删除并开始一个新的 translog。
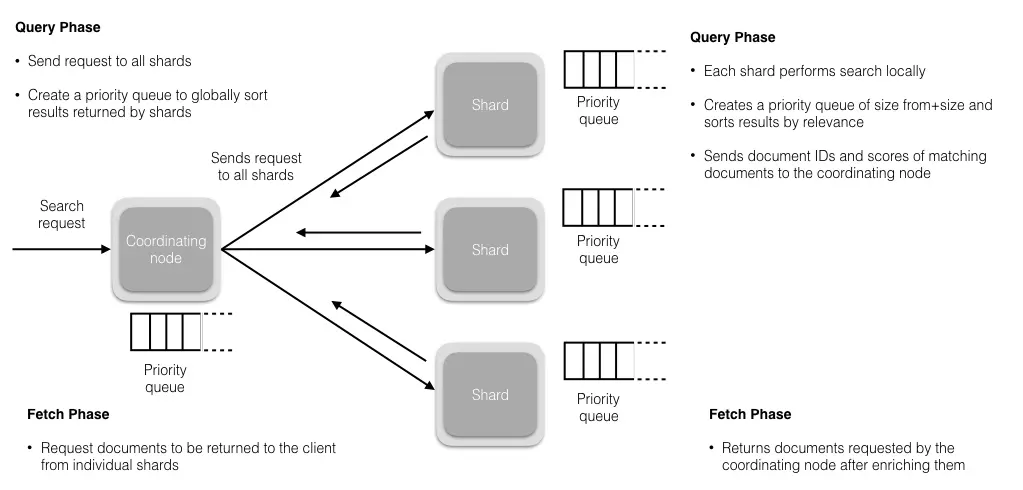
5 读操作
查询阶段
在这个阶段,协调节点会将查询请求路由到索引的全部分片 (主分片或者其副本) 上。每个分片独立执行查询,并为查询结果创建一个优先队列,以相关性得分排序。全部分片都将匹配文档的 ID 及其相关性得分返回给协调节点。协调节点创建一个优先队列并对结果进行全局排序。会有很多文档匹配结果,但是,默认情况下,每个分片只发送前 10 个结果给协调节点,协调节点为全部分片上的这些结果创建优先队列并返回前 10 个作为 hit。
提取阶段
当协调节点在生成的全局有序的文档列表中,为全部结果排好序后,它将向包含原始文档的分片发起请求。全部分片填充文档信息并将其返回给协调节点。