Seata 是什么 分布式事务 Seata 及其三种模式详解
1. 单数据源事务 & 多数据源事务
-
原子性,A
-
一致性,C
-
隔离性,I
-
持久性,D
单个数据库实现自身的事务特性是一个复杂又微妙的过程,例如 MySQL 的 InnoDB 引擎通过 Undo Log + Redo Log + ARIES 算法来实现。
*单数据源事务也可以叫做单机事务,或者本地事务。
在分布式场景下,一个系统由多个子系统构成,每个子系统有独立的数据源。多个子系统之间通过互相调用来组合出更复杂的业务。
在时下流行的微服务系统架构中,每一个子系统被称作一个微服务,同样每个微服务都维护自己的数据库,以保持独立性。
例如,一个电商系统可能由购物微服务、库存微服务、订单微服务等组成。购物微服务通过调用库存微服务和订单微服务来整合出购物业务。用户请求购物微服务商完成下单时,购物微服务一方面调用库存微服务扣减相应商品的库存数量,另一方面调用订单微服务插入订单记录(为了后文描述分布式事务解决方案的方便,这里给出的是一个最简单的电商系统微服务划分和最简单的购物业务流程,后续的支付、物流等业务不在考虑范围内)。电商系统模型如下图所示:
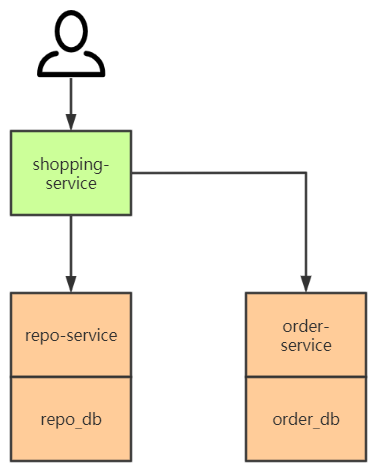
在用户购物的业务场景中,shopping-service 的业务涉及两个数据库:库存库(repo_db)和订单库(repo_db),也就是 g 购物业务是调用多数据源来组合而成的。作为一个面向消费者的系统,电商系统要保证购物业务的高度可靠性,这里的可靠性同样有 ACID 四种语义。
一个数据库的本地事务机制仅仅对落到自己身上的查询操作(这里的查询是广义的,包括增删改查等)起作用,无法干涉对其他数据库的查询操作。所以,数据库自身提供的本地事务机制无法确保业务对多数据源全局操作的可靠性。
2. 常见分布式事务解决方案
2.1. 分布式事务模型
-
事务参与者/资源管理器(Resource Manager, RM):例如每个数据库就是一个事务参与者
-
事务协调者/事务管理器(Transaction Manager, TM):访问多个数据源的服务程序,例如 shopping-service 就是事务协调者
在分布式事务模型中,一个 TM 管理多个 RM,即一个服务程序访问多个数据源;TM 是一个全局事务管理器,协调多方本地事务的进度,使其共同提交或回滚,最终达成一种全局的 ACID 特性。
2.2. 二将军问题和幂等性
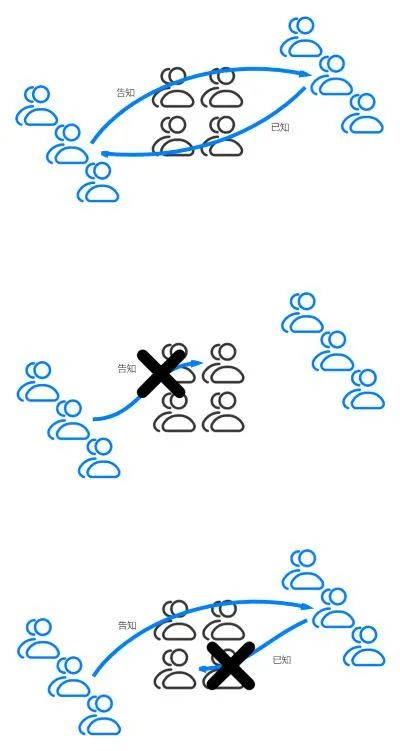
只有当送信士兵成功往返后,总指挥才能确认这场战争的胜利
需要重复发送,接收方需要保证幂等性
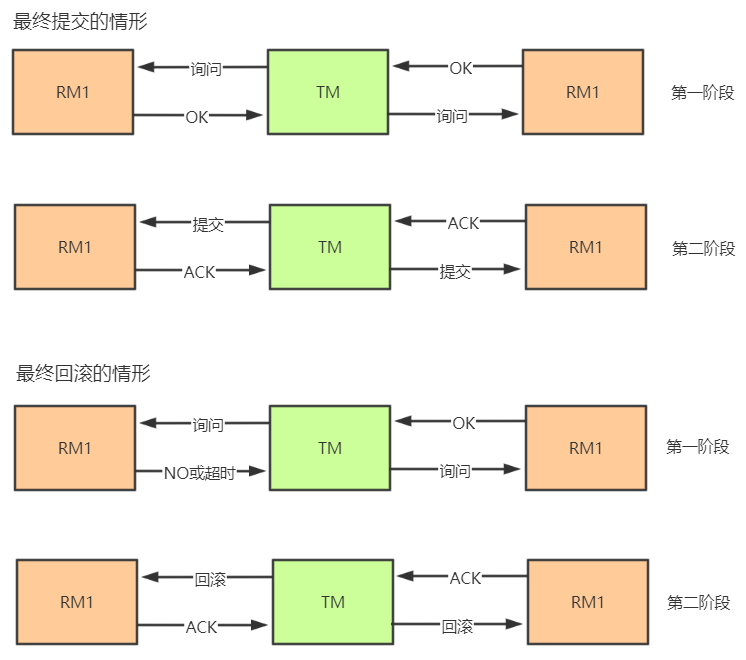
2.3. 两阶段提交(2PC) & 三阶段提交(3PC)方案
2PC 是一种实现分布式事务的简单模型,这两个阶段是:
-
准备阶段:事务协调者向各个事务参与者发起询问请求:“我要执行全局事务了,这个事务涉及到的资源分布在你们这些数据源中,分别是……,你们准备好各自的资源(即各自执行本地事务到待提交阶段)”。各个参与者协调者回复 yes(表示已准备好,允许提交全局事务)或 no(表示本参与者无法拿到全局事务所需的本地资源,因为它被其他本地事务锁住了)或超时。
-
提交阶段:如果各个参与者回复的都是 yes,则协调者向所有参与者发起事务提交操作,然后所有参与者收到后各自执行本地事务提交操作并向协调者发送 ACK;如果任何一个参与者回复 no 或者超时,则协调者向所有参与者发起事务回滚操作,然后所有参与者收到后各自执行本地事务回滚操作并向协调者发送 ACK。
2PC 之后又出现了 3PC,把两阶段过程变成了三阶段过程,分别是:1.询问阶段、2.准备阶段、3.提交或回滚阶段
2PC 除了性能和可靠性上存在问题,它的适用场景也很局限,它要求参与者实现了 XA 协议,例如使用实现了 XA 协议的数据库作为参与者可以完成 2PC 过程。但是在多个系统服务利用 api 接口相互调用的时候,就不遵守 XA 协议了,这时候 2PC 就不适用了。所以 2PC 在分布式应用场景中很少使用。
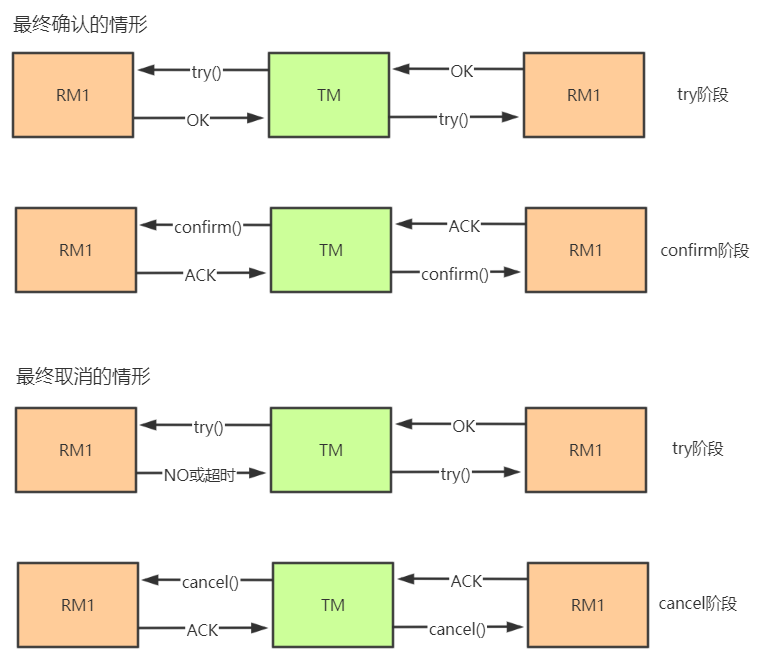
2.4. TCC 方案
描述 TCC 方案使用的电商微服务模型如下图所示,在这个模型中,shopping-service 是事务协调者,repo-service 和 order-service 是事务参与者。

TCC 就是一种解决多个微服务之间的分布式事务问题的方案。TCC 是 Try、Confirm、Cancel 三个词的缩写,其本质是一个应用层面上的 2PC,同样分为两个阶段:
-
准备阶段 :协调者调用所有的每个微服务提供的 try 接口,将整个全局事务涉及到的资源锁定住,若锁定成功 try 接口向协调者返回 yes。
-
提交阶段 :若所有的服务的 try 接口在阶段一都返回 yes,则进入提交阶段,协调者调用所有服务的 confirm 接口,各个服务进行事务提交。如果有任何一个服务的 try 接口在阶段一返回 no 或者超时,则协调者调用所有服务的 cancel 接口。
它是如何解决 2PC 无法应对宕机问题的缺陷的呢? 答案是不断重试
重试就要考虑幂等性
2.5. 事务状态表方案
另外有一种类似 TCC 的事务解决方案,借助事务状态表来实现。假设要在一个分布式事务中实现调用 repo-service 扣减库存、调用 order-service 生成订单两个过程。在这种方案中,协调者 shopping-service 维护一张如下的事务状态表:
| 分布式事务 ID | 事务内容 | 事务状态 |
|---|---|---|
| global_trx_id_1 | 操作 1:调用 repo-service 扣减库存 操作 2:调用 order-service 生成订单 | 状态 1:初始 状态 2:操作 1 成功 状态 3:操作 1、2 成功 |
2.6. 基于消息中间件的最终一致性事务方案
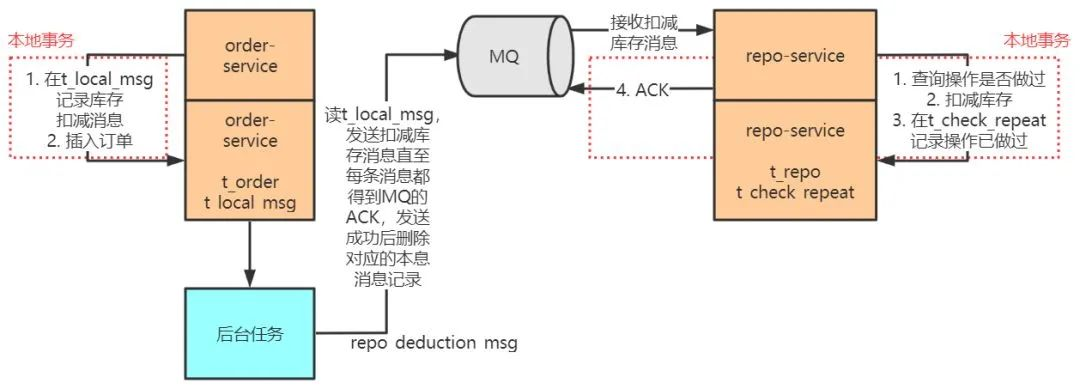
1)order-service 中,
在 t_order 表添加订单记录 &&
在 t_local_msg 添加对应的扣减库存消息
这两个过程要在一个事务中完成,保证过程的原子性。同样,repo-service 中,
检查本次扣库存操作是否已经执行过
&&执行扣减库存如果本次扣减操作没有执行过
&&写判重表
&&向 MQ sever 反馈消息消费完成 ACK
这四个过程也要在一个事务中完成,保证过程的原子性。
2)order-service 中有一个后台程序,源源不断地把消息表中的消息传送给消息中间件,成功后则删除消息表中对应的消息。如果失败了,也会不断尝试重传。
通过这种设计,实现了消息在发送方不丢失,消息在接收方不被重复消费,联合起来就是消息不漏不重,严格实现了 order-service 和 repo-service 的两个数据库中数据的最终一致性。
2.7. SAGA
Saga是由一系列的本地事务构成。每一个本地事务在更新完数据库之后,会发布一条消息或者一个事件来触发Saga中的下一个本地事务的执行。如果一个本地事务因为某些业务规则无法满足而失败,Saga会执行在这个失败的事务之前成功提交的所有事务的补偿操作。
控制(Orchestration)
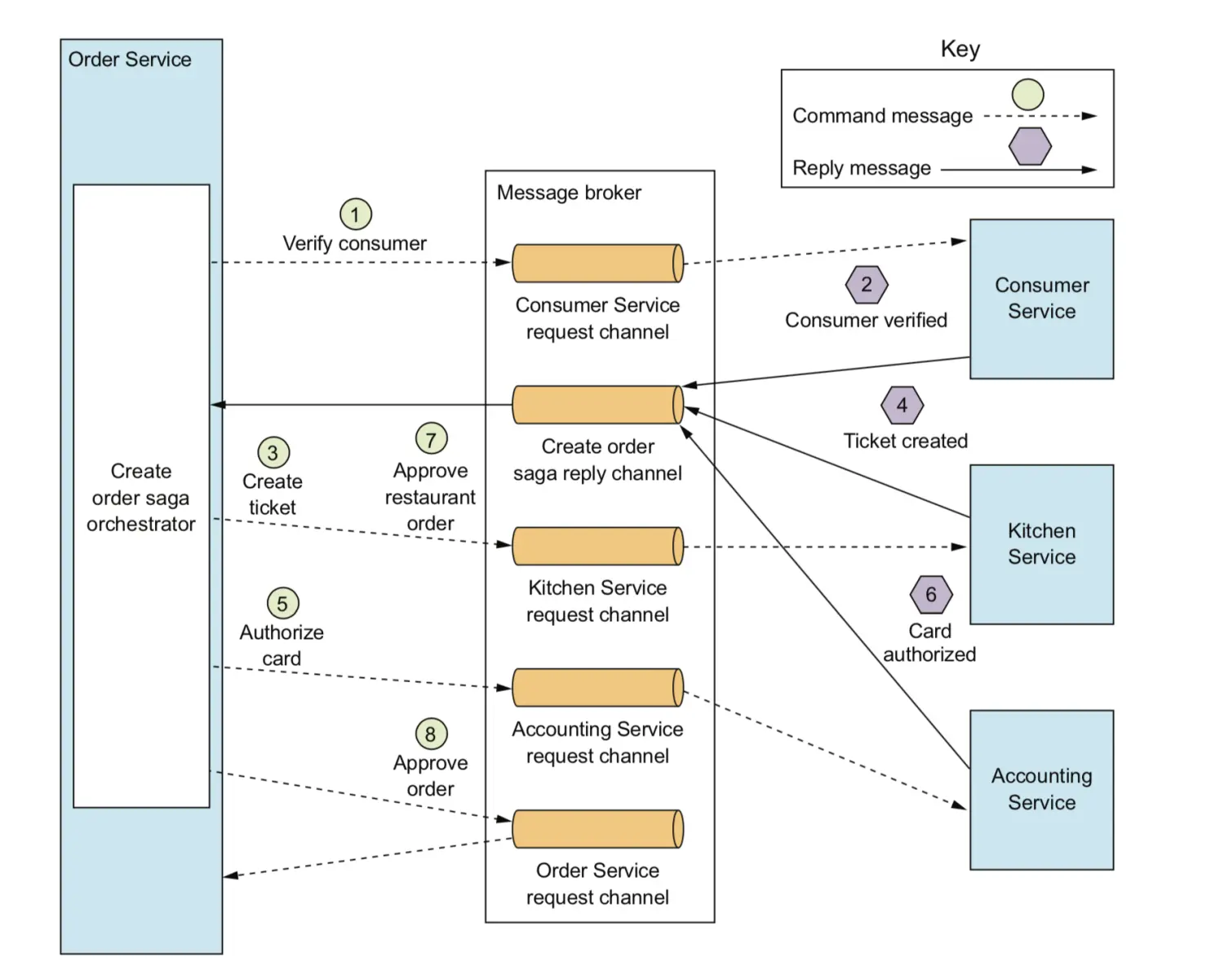
控制是实现sagas的另一种方式。使用业务流程时,您可以定义一个控制类,其唯一的职责是告诉saga参与者该做什么。 saga控制使用命令/异步回复样式交互与参与者进行通信。
- Order Service首先创建一个Order和一个创建订单控制器。之后,路径的流程如下:
- saga orchestrator向Consumer Service发送Verify Consumer命令。
- Consumer Service回复Consumer Verified消息。
- saga orchestrator向Kitchen Service发送Create Ticket命令。
- Kitchen Service回复Ticket Created消息。
- saga协调器向Accounting Service发送授权卡消息。
- Accounting服务部门使用卡片授权消息回复。
- saga orchestrator向Kitchen Service发送Approve Ticket命令。
- saga orchestrator向订单服务发送批准订单命令。
使用状态机建模SAGA ORCHESTRATORS
建模saga orchestrator的好方法是作为状态机。状态机由一组状态和一组由事件触发的状态之间的转换组成。每个transition都可以有一个action,对于一个saga来说是一个saga参与者的调用。状态之间的转换由saga参与者执行的本地事务的完成触发。当前状态和本地事务的特定结果决定了状态转换以及执行的操作(如果有的话)。对状态机也有有效的测试策略。因此,使用状态机模型可以更轻松地设计、实施和测试。
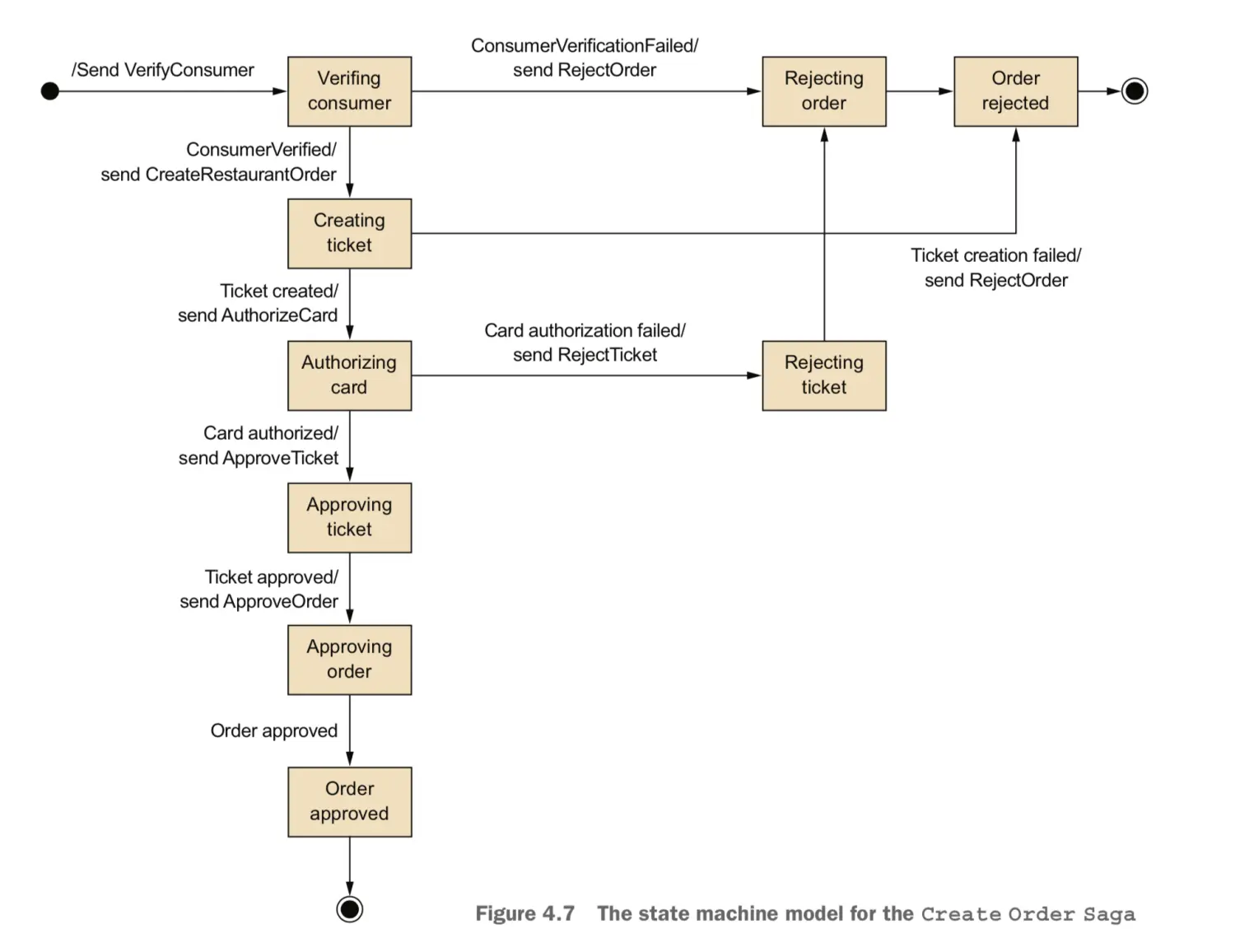 图显示了Create Order Saga的状态机模型。此状态机由多个状态组成,包括以下内容:
图显示了Create Order Saga的状态机模型。此状态机由多个状态组成,包括以下内容:
- Verifying Consumer:初始状态。当处于此状态时,该saga正在等待消费者服务部门验证消费者是否可以下订单。
- Creating Ticket:该saga正在等待对创建票证命令的回复。
- Authorizing Card:等待Accounting服务授权消费者的信用卡。
- OrderApproved:表示saga成功完成的最终状态。
- Order Rejected:最终状态表明该订单被其中一方参与者们拒绝。
AT 模式
AT 模式是一种无侵入的分布式事务解决方案。阿里seata框架,实现了该模式。

AT 模式如何做到对业务的无侵入
- 一阶段:
在一阶段,Seata 会拦截“业务 SQL”,首先解析 SQL 语义,找到“业务 SQL”要更新的业务数据,在业务数据被更新前,将其保存成“before image”,然后执行“业务 SQL”更新业务数据,在业务数据更新之后,再将其保存成“after image”,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。
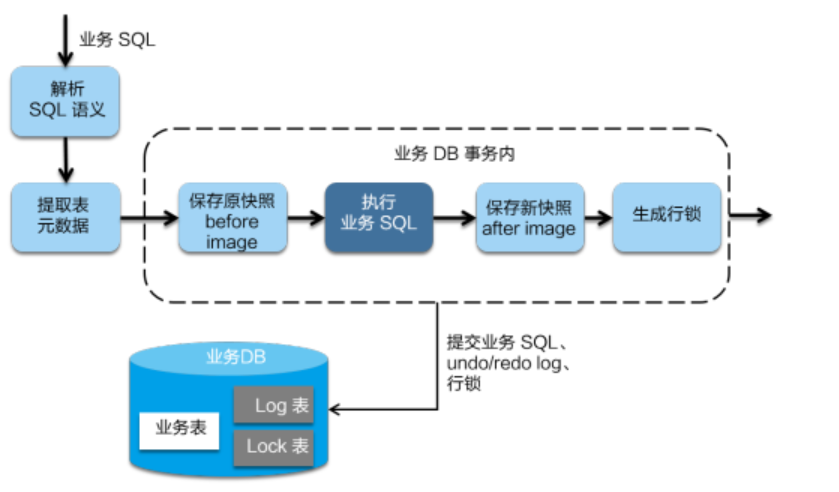
- 二阶段提交:
二阶段如果是提交的话,因为“业务 SQL”在一阶段已经提交至数据库, 所以 Seata 框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。
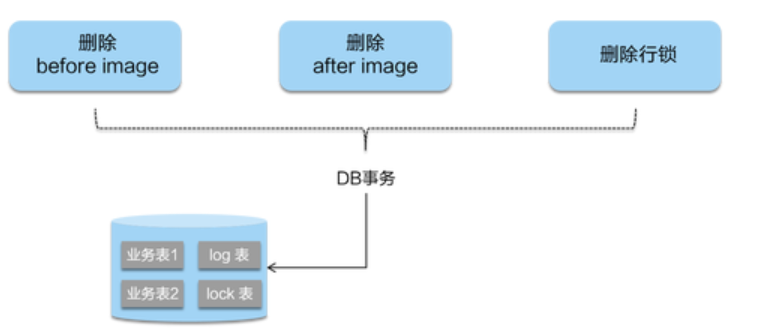
- 二阶段回滚:
二阶段如果是回滚的话,Seata 就需要回滚一阶段已经执行的“业务 SQL”,还原业务数据。回滚方式便是用“before image”还原业务数据;但在还原前要首先要校验脏写,对比“数据库当前业务数据”和 “after image”,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。
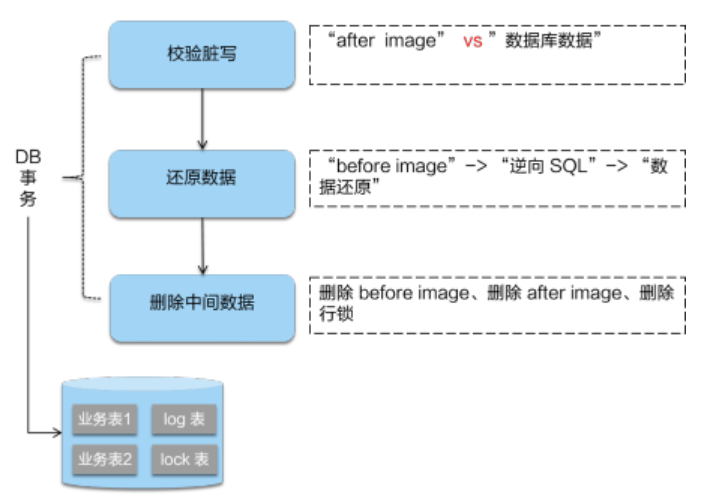
AT 模式的一阶段、二阶段提交和回滚均由 Seata 框架自动生成,用户只需编写“业务 SQL”,便能轻松接入分布式事务,AT 模式是一种对业务无任何侵入的分布式事务解决方案。
- AT 模式是无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本。
- TCC 模式是高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景。
- Saga 模式是长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统,Saga 模式一阶段就会提交本地事务,无锁,长流程情况下可以保证性能,多用于渠道层、集成层业务系统。事务参与者可能是其它公司的服务或者是遗留系统的服务,无法进行改造和提供 TCC 要求的接口,也可以使用 Saga 模式。
- XA模式是分布式强一致性的解决方案,但性能低而使用较少。