JAVA 中文件IO有几种方式?
原生的读写方式大概可以被分为三种:普通IO,FileChannel(文件通道),MMAP(内存映射)。区分他们也很简单,例如 FileWriter,FileReader 存在于 java.io 包中,他们属于普通IO;FileChannel 存在于 java.nio 包中,属于 NIO 的一种,但是注意 NIO 并不一定意味着非阻塞,这里的 FileChannel 就是阻塞的;较为特殊的是后者 MMAP,它是由 FileChannel 调用 map 方法衍生出来的一种特殊读写文件的方式,被称之为内存映射。
使用 FIleChannel 的方式:
1
2
FileChannel fileChannel = new RandomAccessFile(new File("db.data"), "rw").getChannel();
获取mmap方式:
1
2
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, filechannel.size();
MappedByteBuffer 便是 JAVA 中 MMAP 的操作类。
FileChannel 读写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// 写
byte[] data = new byte[4096];
long position = 1024L;
// 指定 position 写入 4kb 的数据
fileChannel.write(ByteBuffer.wrap(data), position);
// 从当前文件指针的位置写入 4kb 的数据
fileChannel.write(ByteBuffer.wrap(data));
// 读
ByteBuffer buffer = ByteBuffer.allocate(4096);
long position = 1024L;
// 指定 position 读取 4kb 的数据
fileChannel.read(buffer,position);
// 从当前文件指针的位置读取 4kb 的数据
fileChannel.read(buffer);
FileChannel 大多数时候是和 ByteBuffer 这个类打交道,你可以将它理解为一个 byte[] 的封装类,提供了丰富的 API 去操作字节,不了解的同学可以去熟悉下它的 API。值得一提的是,write 和 read 方法均是 线程安全 的,FileChannel 内部通过一把 private final Object positionLock = new Object(); 锁来控制并发。
FileChannel 为什么比普通 IO 要快呢?这么说可能不严谨,因为你要用对它,FileChannel 只有在一次写入 4kb 的整数倍时,才能发挥出实际的性能,这得益于 FileChannel 采用了 ByteBuffer 这样的内存缓冲区,让我们可以非常精准的控制写盘的大小,这是普通 IO 无法实现的。4kb 一定快吗?也不严谨,这主要取决你机器的磁盘结构,并且受到操作系统,文件系统,CPU 的影响
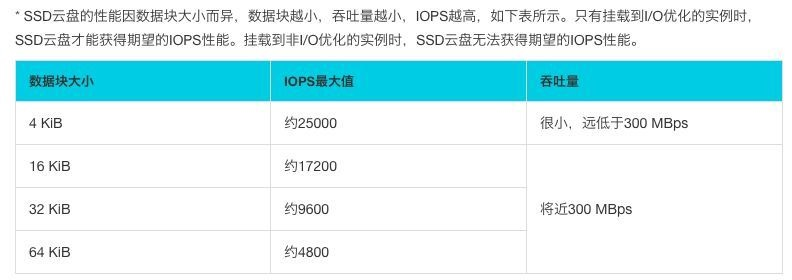
另外一点,成就了 FileChannel 的高效,介绍这点之前,我想做一个提问:FileChannel 是直接把 ByteBuffer 中的数据写入到磁盘吗?思考几秒…答案是:NO。ByteBuffer 中的数据和磁盘中的数据还隔了一层,这一层便是 PageCache,是用户内存和磁盘之间的一层缓存。我们都知道磁盘 IO 和内存 IO 的速度可是相差了好几个数量级。我们可以认为 filechannel.write 写入 PageCache 便是完成了落盘操作,但实际上,操作系统最终帮我们完成了 PageCache 到磁盘的最终写入,理解了这个概念,你就应该能够理解 FileChannel 为什么提供了一个 force() 方法,用于通知操作系统进行及时的刷盘。
同理,当我们使用 FileChannel 进行读操作时,同样经历了:磁盘->PageCache->用户内存这三个阶段
MMAP 读写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// 写
byte[] data = new byte[4];
int position = 8;
// 从当前 mmap 指针的位置写入 4b 的数据
mappedByteBuffer.put(data);
// 指定 position 写入 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.put(data);
// 读
byte[] data = new byte[4];
int position = 8;
// 从当前 mmap 指针的位置读取 4b 的数据
mappedByteBuffer.get(data);
// 指定 position 读取 4b 的数据
MappedByteBuffer subBuffer = mappedByteBuffer.slice();
subBuffer.position(position);
subBuffer.get(data);
当我们执行 fileChannel.map(FileChannel.MapMode.READ_WRITE, 0, 1.5 * 1024 * 1024 * 1024); 之后,观察一下磁盘上的变化,会立刻获得一个 1.5G 的文件,但此时文件的内容全部是 0(字节 0)。这符合 MMAP 的中文描述:内存映射文件,我们之后对内存中 MappedByteBuffer 做的任何操作,都会被最终映射到文件之中,
mmap 把
文件映射到用户空间里的虚拟内存,省去了从内核缓冲区复制到用户空间的过程,文件中的位置在虚拟内存中有了对应的地址,可以像操作内存一样操作这个文件,相当于已经把整个文件放入内存,但在真正使用到这些数据前却不会消耗物理内存,也不会有读写磁盘的操作,只有真正使用这些数据时,也就是图像准备渲染在屏幕上时,虚拟内存管理系统 VMS 才根据缺页加载的机制从磁盘加载对应的数据块到物理内存进行渲染。这样的文件读写文件方式少了数据从内核缓存到用户空间的拷贝,效率很高
看了稍微官方一点的描述,你可能对 MMAP 有了些许的好奇,有这么厉害的黑科技存在的话,还有 FileChannel 存在的意义吗!并且网上很多文章都在说,MMAP 操作大文件性能比 FileChannel 搞出一个数量级!然而,通过我比赛的认识,MMAP 并非是文件 IO 的银弹,它只有在 一次写入很小量数据的场景 下才能表现出比 FileChannel 稍微优异的性能。紧接着我还要告诉你一些令你沮丧的事,至少在 JAVA 中使用 MappedByteBuffer 是一件非常麻烦并且痛苦的事,主要表现为三点:
- MMAP 使用时必须实现指定好内存映射的大小,并且一次 map 的大小限制在 1.5G 左右,重复 map 又会带来虚拟内存的回收、重新分配的问题,对于文件不确定大小的情形实在是太不友好了。
- MMAP 使用的是虚拟内存,和 PageCache 一样是由操作系统来控制刷盘的,虽然可以通过 force() 来手动控制,但这个时间把握不好,在小内存场景下会很令人头疼。
- MMAP 的回收问题,当 MappedByteBuffer 不再需要时,可以手动释放占用的虚拟内存,但…方式非常的诡异。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
public static void clean(MappedByteBuffer mappedByteBuffer) {
ByteBuffer buffer = mappedByteBuffer;
if (buffer == null || !buffer.isDirect() || buffer.capacity()== 0)
return;
invoke(invoke(viewed(buffer), "cleaner"), "clean");
}
private static Object invoke(final Object target, final String methodName, final Class<?>... args) {
return AccessController.doPrivileged(new PrivilegedAction<Object>() {
public Object run() {
try {
Method method = method(target, methodName, args);
method.setAccessible(true);
return method.invoke(target);
} catch (Exception e) {
throw new IllegalStateException(e);
}
}
});
}
private static Method method(Object target, String methodName, Class<?>[] args)
throws NoSuchMethodException {
try {
return target.getClass().getMethod(methodName, args);
} catch (NoSuchMethodException e) {
return target.getClass().getDeclaredMethod(methodName, args);
}
}
private static ByteBuffer viewed(ByteBuffer buffer) {
String methodName = "viewedBuffer";
Method[] methods = buffer.getClass().getMethods();
for (int i = 0; i < methods.length; i++) {
if (methods[i].getName().equals("attachment")) {
methodName = "attachment";
break;
}
}
ByteBuffer viewedBuffer = (ByteBuffer) invoke(buffer, methodName);
if (viewedBuffer == null)
return buffer;
else
return viewed(viewedBuffer);
}
这么长的代码仅仅是为了干回收 MappedByteBuffer 这一件事。
优先使用 FileChannel 去完成初始代码的提交,在必须使用小数据量 (例如几个字节) 刷盘的场景下,再换成 MMAP 的实现,其他场景 FileChannel 完全可以 cover(前提是你理解怎么合理使用 FileChannel)。至于 MMAP 为什么在一次写入少量数据的场景下表现的比 FileChannel 优异,我还没有查到理论根据,如果你有相关的线索,欢迎留言。理论分析下,FileChannel 同样是写入内存,但是在写入小数据量时,MMAP 表现的更加优秀,所以在索引数据落盘时,大多数情况应该选择使用 MMAP。至于 MMAP 分配的虚拟内存是否就是真正的 PageCache 这一点,我觉得可以近似理解成 PageCache。
顺序读比随机读快,顺序写比随机写快
首先,什么是顺序读,什么是随机读,什么是顺序写,什么是随机写?可能我们刚接触文件 IO 操作时并不会有这样的疑惑,但写着写着,自己都开始怀疑自己的理解了,不知道你有没有经历过这样类似的阶段,反正我有一段时间的确怀疑过。那么,先来看看两段代码:
写入方式一:64 个线程,用户自己使用一个 atomic 变量记录写入指针的位置,并发写入
1
2
3
4
5
6
7
8
ExecutorService executor = Executors.newFixedThreadPool(64);
AtomicLong wrotePosition = new AtomicLong(0);
for(int i=0;i<1024;i++){
final int index = i;
executor.execute(()->{
fileChannel.write(ByteBuffer.wrap(new byte[4*1024]),wrote.getAndAdd(4*1024));
})
}
写入方式二:给 write 加了锁,保证了同步。
1
2
3
4
5
6
7
8
9
10
11
12
ExecutorService executor = Executors.newFixedThreadPool(64);
AtomicLong wrotePosition = new AtomicLong(0);
for(int i=0;i<1024;i++){
final int index = i;
executor.execute(()->{
write(new byte[4*1024]);
})
}
public synchronized void write(byte[] data){
fileChannel.write(ByteBuffer.wrap(new byte[4*1024]),wrote.getAndAdd(4*1024));
}
答案是方式二才算顺序写,顺序读也是同理。对于文件操作,加锁并不是一件非常可怕的事,不敢同步 write/read 才可怕!有人会问:FileChannel 内部不是已经有 positionLock 保证写入的线程安全了吗,为什么还要自己加同步?为什么这样会快?我用大白话来回答的话就是多线程并发 write 并且不加同步,会导致文件空洞,它的执行次序可能是
时序 1:thread1 write position[0~4096)
时序 2:thread3 write position[8194~12288)
时序 3:thread2 write position[4096~8194)
所以并不是完全的“顺序写”。不过你也别担心加锁会导致性能下降,我们会在下面的小结介绍一个优化:通过文件分片来减少多线程读写时锁的冲突。
在来分析原理,顺序读为什么会比随机读要快?顺序写为什么比随机写要快?这两个对比其实都是一个东西在起作用:PageCache,前面我们已经提到了,它是位于 application buffer(用户内存) 和 disk file(磁盘) 之间的一层缓存。
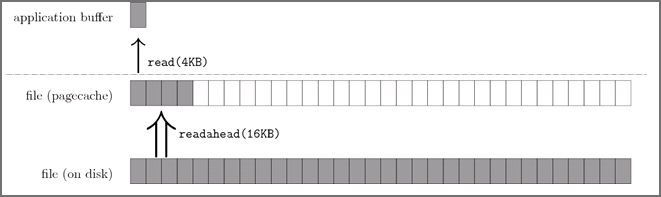
以顺序读为例,当用户发起一个 fileChannel.read(4kb) 之后,实际发生了两件事
- 操作系统从磁盘加载了 16kb 进入 PageCache,这被称为
预读 - 操作通从 PageCache 拷贝 4kb 进入用户内存
最终我们在用户内存访问到了 4kb,为什么顺序读快?很容量想到,当用户继续访问接下来的[4kb,16kb]的磁盘内容时,便是直接从 PageCache 去访问了。试想一下,当需要访问 16kb 的磁盘内容时,是发生4次磁盘 IO 快,还是发生1次磁盘 IO+4 次内存 IO 快呢?答案是显而易见的,这一切都是 PageCache 带来的优化。
深度思考:当内存吃紧时,PageCache 的分配会受影响吗?PageCache 的大小如何确定,是固定的 16kb 吗?我可以监控 PageCache 的命中情况吗? PageCache 会在哪些场景失效,如果失效了,我们又要哪些补救方式呢?
我进行简单的自问自答,背后的逻辑还需要读者去推敲:
- 当内存吃紧时,PageCache 的预读会受到影响,实测,并没有搜到到文献支持
- PageCache 是动态调整的,可以通过 linux 的系统参数进行调整,默认是占据总内存的 20%
- https://github.com/brendangregg/perf-tools github 上一款工具可以监控 PageCache
- 这是很有意思的一个优化点,如果用 PageCache 做缓存不可控,不妨自己做预读如何呢?
直接内存 VS 堆内内存
前面 FileChannel 的示例代码中已经使用到了堆内内存: ByteBuffer.allocate(4*1024),ByteBuffer 提供了另外的方式让我们可以分配堆外内存 : ByteBuffer.allocateDirect(4*1024)。这就引来的一系列的问题,我什么时候应该使用堆内内存,什么时候应该使用直接内存?
| 堆内内存 | 堆外内存 | |
|---|---|---|
| ** 底层实现 ** | 数组,JVM 内存 | unsafe.allocateMemory(size) 返回直接内存 |
| 垃圾回收 | 不说 | 当 DirectByteBuffer 不再被使用时,会出发内部 cleaner 的钩子,保险起见,可以考虑手动回收:((DirectBuffer) buffer).cleaner().clean(); |
| 内存复制 | 堆内内存 -> 堆外内存 -> pageCache | 堆外内存 -> pageCache |
关于堆内内存和堆外内存的一些最佳实践:
- 当需要申请大块的内存时,堆内内存会受到限制,只能分配堆外内存。
- 堆外内存适用于生命周期中等或较长的对象。( 如果是生命周期较短的对象,在 YGC 的时候就被回收了,就不存在大内存且生命周期较长的对象在 FGC 对应用造成的性能影响 )。
- 堆内内存刷盘的过程中,还需要复制一份到堆外内存,这部分内容可以在 FileChannel 的实现源码中看到细节
- 同时,还可以使用池+堆外内存 的组合方式,来对生命周期较短,但涉及到 I/O 操作的对象进行堆外内存的再使用( Netty中就使用了该方式 )。在比赛中,尽量不要出现 频繁 newbyte[] ,创建内存区域再回收也是一笔不小的开销,使用 ThreadLocal
和 ThreadLocal<byte[]> 往往会给你带来意外的惊喜~ - 创建堆外内存的消耗要大于创建堆内内存的消耗,所以当分配了堆外内存之后,尽可能复用它。
黑魔法:UNSAFE
1
2
3
4
5
6
7
8
9
10
11
12
public class UnsafeUtil {
public static final Unsafe UNSAFE;
static {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
UNSAFE = (Unsafe) field.get(null);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
我们可以使用 UNSAFE 这个黑魔法实现很多无法想象的事,我这里就稍微介绍一两点吧。
实现直接内存与内存的拷贝:
1
2
3
4
ByteBuffer buffer = ByteBuffer.allocateDirect(4 * 1024 * 1024);
long addresses = ((DirectBuffer) buffer).address();
byte[] data = new byte[4 * 1024 * 1024];
UNSAFE.copyMemory(data, 16, null, addresses, 4 * 1024 * 1024);
copyMemory 方法可以实现内存之间的拷贝,无论是堆内和堆外,1~2 个参数是 source 方,3~4 是 target 方,第 5 个参数是 copy 的大小。如果是堆内的字节数组,则传递数组的首地址和 16 这个固定的 ARRAYBYTEBASE_OFFSET 偏移常量;如果是堆外内存,则传递 null 和直接内存的偏移量,可以通过 ((DirectBuffer) buffer).address() 拿到。为什么不直接拷贝,而要借助 UNSAFE?当然是因为它快啊!少年!另外补充:MappedByteBuffer 也可以使用 UNSAFE 来 copy 从而达到写盘/读盘的效果哦。
至于 UNSAFE 还有那些黑科技,可以专门去了解下,我这里就不过多赘述了。
文件分区
前面已经提到了顺序读写时我们需要对 write,read 加锁,并且我一再强调的一点是:加锁并不可怕,文件 IO 操作并没有那么依赖多线程。但是加锁之后的顺序读写必然无法打满磁盘 IO,如今系统强劲的 CPU 总不能不压榨吧?我们可以采用文件分区的方式来达到一举两得的效果:既满足了顺序读写,又减少了锁的冲突。
那么问题又来了,分多少合适呢?文件多了,锁冲突变降低了;文件太多了,碎片化太过严重,单个文件的值太少,缓存也就不容易命中,这样的 trade off 如何平衡?没有理论答案,benchmark everything~
Direct IO
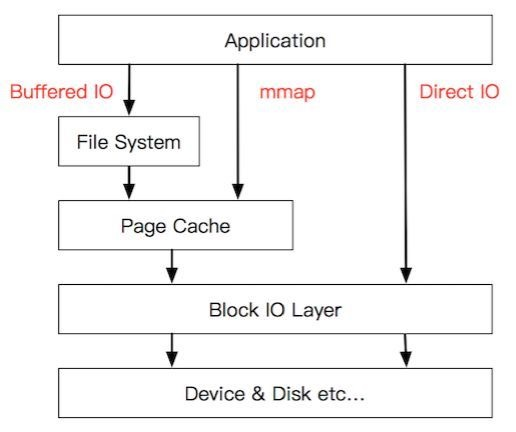 严谨来说,这并不是 JAVA 原生支持的方式,但可以通过 JNA/JNI 调用 native 方法做到。从上图我们可以看到 :Direct IO 绕过了 PageCache,但我们前面说到过,PageCache 可是个好东西啊,干嘛不用他呢?再仔细推敲一下,还真有一些场景下,Direct IO 可以发挥作用,没错,那就是我们前面没怎么提到的:随机读。当使用 fileChannel.read() 这类会触发 PageCache 预读的 IO 方式时,我们其实并不希望操作系统帮我们干太多事,除非真的踩了狗屎运,随机读都能命中 PageCache,但几率可想而知。Direct IO 虽然被 Linus 无脑喷过,但在随机读的场景下,依旧存在其价值,减少了 Block IO Layed(近似理解为磁盘) 到 Page Cache 的 overhead。
严谨来说,这并不是 JAVA 原生支持的方式,但可以通过 JNA/JNI 调用 native 方法做到。从上图我们可以看到 :Direct IO 绕过了 PageCache,但我们前面说到过,PageCache 可是个好东西啊,干嘛不用他呢?再仔细推敲一下,还真有一些场景下,Direct IO 可以发挥作用,没错,那就是我们前面没怎么提到的:随机读。当使用 fileChannel.read() 这类会触发 PageCache 预读的 IO 方式时,我们其实并不希望操作系统帮我们干太多事,除非真的踩了狗屎运,随机读都能命中 PageCache,但几率可想而知。Direct IO 虽然被 Linus 无脑喷过,但在随机读的场景下,依旧存在其价值,减少了 Block IO Layed(近似理解为磁盘) 到 Page Cache 的 overhead。
话说回来,Java 怎么用 Direct IO 呢?有没有什么限制呢?前面说过,Java 目前原生并不支持,但也有好心人封装好了 Java 的 JNA 库,实现了 Java 的 Direct IO,github 地址:https://github.com/smacke/jaydio
1
2
3
4
5
6
7
8
int bufferSize = 20 * 1024 * 1024;
DirectRandomAccessFile directFile = new DirectRandomAccessFile(new File("dio.data"), "rw", bufferSize);
for(int i= 0;i< bufferSize / 4096;i++){
byte[] buffer = new byte[4 * 1024];
directFile.read(buffer);
directFile.readFully(buffer);
}
directFile.close();
但需要注意的是, 只有 Linux 系统才支持 DIO! 所以,少年,是时候上手装一台 linux 了。值得一提的是,据说在 Jdk10 发布之后,Direct IO 将会得到原生的支持

既然FileChannel与MappedByteBuffer毫无关系,为什么commit之后的数据,就可以在MappedByteBuffer中能读取的到?
Page cache
页缓存是Linux系统内核实现磁盘缓存。它主要用来减少对磁盘的I/O操作。具体的讲,是通过把磁盘中的数据缓存到物理内存中,把对磁盘的访问变为对物理内存的访问。
我们的MappedByteBuffer就是通过mmap出来的一部分page cache。
而linux的写数据又采用了write-back的策略,即写操作直接写到缓存中,后端存储不会立即直接更新,而是将page cache中被写入的页标记为“脏页”,并且被加入到脏页列表中。等待write-back进程或者用户手动刷盘,将脏页列表中的页数据写回到磁盘,再清理“脏页”标识。
所以FileChannel写数据(commit)后,实际也是写到了page cache中,而FileChannel与MappedByteBuffer映射的是同一份物理文件,所以都映射的相同的page cache。通过FileChannel commit后的数据,在MappedByteBuffer中即为可见。
既然利用了linux的page cache,减少了内核空间与用户空间的数据拷贝,那么也要承受其带来的问题,缺页异常与缓存回收。
缺页异常
Major page faults就是我们常说的page faults了,数据不在物理内存page cache中,就需要访问磁盘读取数据,再放到物理内存中。
而实际上linux采用的都是“copy on write”(注意这里与我们Java中的CopyOnWrite系列集合不是一个概念),即mmap的时候,不会实际分配物理内存,而只是提前分配了虚拟内存,只有当真正去使用这些数据的时候,才会通过page faults实际映射文件。
在RocketMQ中为了避免这种“copy on write”的策略,采用了预热的方式,创建并mmap文件后,提前把每页都写一个字节的数据。
MappedFile.warmMappedFile
缓存回收
物理内存毕竟有限,为了给更重要的数据腾出空间或者收缩缓存空间,需要把一部分page清除。linux采用双链策略,即维护两个LRU链表:活跃链表与非活跃链表。只会替换非活跃链表缓存,活跃链表的缓存都从非活跃链表晋升而来。这就带来了一个问题,我们辛辛苦苦映射到物理内存的page cache,如果被换出,再次访问时又需要page faults。所以在RocketMQ中采用了内存锁定,通过mlock使得我们创建的DirectBuffer和MappedByteBuffer不会被换出。
为什么写DirectBuffer而不是HeapBuffer
我们看FileChannel的write方法,最终调用了IOUtil的write方法,在写数据时会判断是否为DirectBuffer,如果不是的话,会临时创建DirectBuffer并拷贝数据,再通过DirectBuffer写数据。这是为了避免写数据时,发生GC导致数据发生变化。所以采用DirectBuffer省去了拷贝数据的过程,进一步提高了性能。
既然无论是写MappedByteBuffer还是写DirectBuffer,最终都是先写到了page cache中,又是如何做到读写分离的?
在RocketMQ中,数据写入到DirectBuffer中不会立即commit,而是需要积攒若干页(默认4页)后,批量commit。一方面是为了提高性能,减少了操作系统脏页刷新的频率。另一方面也正是做到了读写分离。因为commit以整页为单位,没有被commit的数据是不会被读取到,所以不会出现同时读写同一page的情况。并且commit是批量定时进行,又进一步减少了page cache读写冲突的概率。
下linux脏页刷盘的三种场景:
- 空闲内存低于一定阈值时,linux会写回脏页以便释放内存。
- 脏页驻留时间超过一定阈值,linux会写回脏页。
- 用户进行手动触发。
综上,RocketMQ在设计层面实现了读写分离的效果,并且在性能方面做到了很极致。同样事情都有利弊,这也导致了数据消费的及时性,即数据必须要等到commit后才可以被消费到。